publications
2026
-
 Zebra-cot: A dataset for interleaved vision language reasoningAng Li , Charles Wang , Deqing Fu , Kaiyu Yue , Zikui Cai , Wang Bill Zhu , Ollie Liu , Peng Guo , Willie Neiswanger , Furong Huang , Tom Goldstein , and Micah GoldblumInternational Conference on Learning Representations (ICLR), 2026
Zebra-cot: A dataset for interleaved vision language reasoningAng Li , Charles Wang , Deqing Fu , Kaiyu Yue , Zikui Cai , Wang Bill Zhu , Ollie Liu , Peng Guo , Willie Neiswanger , Furong Huang , Tom Goldstein , and Micah GoldblumInternational Conference on Learning Representations (ICLR), 2026Humans often rely on visual aids, such as diagrams or sketches, when tackling complex problems. Teaching multimodal models to adopt similar strategies, a process known as Visual Chain of Thought (visual CoT), is much more difficult. The main challenges are: (1) weak performance of off-the-shelf visual CoT, which hinders reinforcement learning, and (2) the lack of high-quality visual CoT training data. We introduce Zebra-CoT a diverse large-scale interleaved text-image reasoning dataset with 182,384 reasoning traces across 18 domains with over 50 distinct tasks. This dataset is specifically designed to train models to natively perform visual CoT. We emphasize four categories of tasks where sketching or visual reasoning is especially natural, spanning (a) scientific questions such as geometry, physics, and algorithms; (b) 2D visual reasoning tasks like visual search and jigsaw puzzles; (c) 3D reasoning tasks including 3D multi-hop inference, embodied and robot planning; and (d) visual logic problems and strategic games like chess. Fine-tuning Anole‑7B model on Zebra-CoT yields a +12% improvement in our test‑set accuracy and up to +13% performance gains on standard VLM benchmarks. Similarly, fine-tuning Bagel‑7B produces models capable of generating high-quality interleaved visual reasoning chains, underscoring Zebra-CoT’s effectiveness in advancing multimodal reasoning.
-
 Identifying and Evaluating Inactive Heads in Pretrained LLMsPedro Sandoval-Segura , Xijun Wang , Ashwinee Panda , Micah Goldblum , Ronen Basri , Tom Goldstein , and David JacobsInternational Conference on Learning Representations (ICLR), 2026
Identifying and Evaluating Inactive Heads in Pretrained LLMsPedro Sandoval-Segura , Xijun Wang , Ashwinee Panda , Micah Goldblum , Ronen Basri , Tom Goldstein , and David JacobsInternational Conference on Learning Representations (ICLR), 2026Attention is foundational to large language models (LLMs), enabling different heads to have diverse focus on relevant input tokens. However, learned behaviors like attention sinks, where the first token receives the most attention despite limited semantic importance, suggest some heads may be inactive, and point to a significant source of computational redundancy. To analyze this phenomenon, we propose a taxonomy of 12 score functions that measure different ways a head can be inactive. Thresholding these scores allows us to analyze different sets of potentially inactive attention heads. We evaluate whether identified heads are inactive through model interventions, finding that more than 12% of attention heads are inactive on average, and can be ablated in specific contexts while maintaining MMLU accuracy to within 1% of the pretrained LLM. Across 3 model families, our score functions that measure the average norm of a head’s output consistently identify inactive heads that would not have been found by score functions that rely solely on attention weights. We establish that relying on a score function that measures a first token attention sink would underestimate the prevalence of inactive heads, failing to identify more than 7% of inactive heads on average. We also show how measuring score distributions can provide insights into attention behavior. For instance, we find evidence that finetuning causes little to no change in attention behavior, and that even within the same model family, large model scales present markedly different attention behaviors.
-
 Vista4D: Video Reshooting with 4D Point CloudsKuan Heng Lin , Zhizheng Liu , Pablo Salamanca , Yash Kant , Ryan Burgert , Yuancheng Xu , Koichi Namekata , Yiwei Zhao , Bolei Zhou , Micah Goldblum , Paul Debevec , and Ning YuComputer Vision and Pattern Recognition Conference (CVPR), 2026
Vista4D: Video Reshooting with 4D Point CloudsKuan Heng Lin , Zhizheng Liu , Pablo Salamanca , Yash Kant , Ryan Burgert , Yuancheng Xu , Koichi Namekata , Yiwei Zhao , Bolei Zhou , Micah Goldblum , Paul Debevec , and Ning YuComputer Vision and Pattern Recognition Conference (CVPR), 2026We present Vista4D, a robust and flexible video reshooting framework that grounds the input video and target cameras in a 4D point cloud. Specifically, given an input video, our method re-synthesizes the scene with the same dynamics from a different camera trajectory and viewpoint. Existing video reshooting methods often struggle with depth estimation artifacts of real-world dynamic videos, while also failing to preserve content appearance and maintain precise camera control for challenging new trajectories. We build a 4D-grounded point cloud representation with static pixel segmentation and 4D reconstruction to explicitly preserve seen content and provide rich camera signals, and we train with reconstructed multiview dynamic data for robustness against point cloud artifacts during real-world inference. Our results demonstrate improved 4D consistency, camera control, and visual quality compared to state-of-the-art baselines under a variety of videos and camera paths. Moreover, our method generalizes to real-world applications such as dynamic scene expansion and 4D scene recomposition.



2025
-
 Livebench: A challenging, contamination-free llm benchmarkColin White , Samuel Dooley , Manley Roberts , Arka Pal , Ben Feuer , Siddhartha Jain , Ravid Shwartz-Ziv , Neel Jain , Khalid Saifullah , Siddartha Naidu , Chinmay Hegde , Yann LeCun , Tom Goldstein , Willie Neiswanger , and Micah GoldblumInternational Conference on Learning Representations (ICLR), 2025
Livebench: A challenging, contamination-free llm benchmarkColin White , Samuel Dooley , Manley Roberts , Arka Pal , Ben Feuer , Siddhartha Jain , Ravid Shwartz-Ziv , Neel Jain , Khalid Saifullah , Siddartha Naidu , Chinmay Hegde , Yann LeCun , Tom Goldstein , Willie Neiswanger , and Micah GoldblumInternational Conference on Learning Representations (ICLR), 2025Test set contamination, wherein test data from a benchmark ends up in a newer model’s training set, is a well-documented obstacle for fair LLM evaluation and can quickly render benchmarks obsolete. To mitigate this, many recent benchmarks crowdsource new prompts and evaluations from human or LLM judges; however, these can introduce significant biases, and break down when scoring hard questions. In this work, we introduce a new benchmark for LLMs designed to be immune to both test set contamination and the pitfalls of LLM judging and human crowdsourcing. We release LiveBench, the first benchmark that (1) contains frequently-updated questions from recent information sources, (2) scores answers automatically according to objective ground-truth values, and (3) contains a wide variety of challenging tasks, spanning math, coding, reasoning, language, instruction following, and data analysis. To achieve this, LiveBench contains questions that are based on recently-released math competitions, arXiv papers, news articles, and datasets, and it contains harder, contamination-free versions of tasks from previous benchmarks such as Big-Bench Hard, AMPS, and IFEval. We evaluate many prominent closed-source models, as well as dozens of open-source models ranging from 0.5B to 110B in size. LiveBench is difficult, with top models achieving below 65% accuracy. We release all questions, code, and model answers. Questions will be added and updated on a monthly basis, and we will release new tasks and harder versions of tasks over time so that LiveBench can distinguish between the capabilities of LLMs as they improve in the future. We welcome community engagement and collaboration for expanding the benchmark tasks and models.
-
 Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation is WastefulMartin Marek , Sanae Lotfi , Aditya Somasundaram , Andrew Gordon Wilson , and Micah GoldblumAdvances in Neural Information Processing Systems (NeurIPS), 2025
Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation is WastefulMartin Marek , Sanae Lotfi , Aditya Somasundaram , Andrew Gordon Wilson , and Micah GoldblumAdvances in Neural Information Processing Systems (NeurIPS), 2025Conventional wisdom dictates that small batch sizes make language model pretraining and fine-tuning unstable, motivating gradient accumulation, which trades off the number of optimizer steps for a proportional increase in batch size. While it is common to decrease the learning rate for smaller batch sizes, other hyperparameters are often held fixed. In this work, we revisit small batch sizes all the way down to batch size one, and we propose a rule for scaling Adam hyperparameters to small batch sizes. In particular, rather than holding the decay rate of the second moment fixed across batch sizes, we propose to hold its half-life fixed in terms of tokens. We find that small batch sizes (1) train stably, (2) are consistently more robust to hyperparameter choices, (3) achieve equal or better per-FLOP performance than larger batch sizes, and (4) notably enable stable language model training with vanilla SGD, even without momentum, despite storing no optimizer state. Building on these results, we provide practical recommendations for selecting a batch size and setting optimizer hyperparameters. We further recommend against gradient accumulation unless training on multiple devices with multiple model replicas. Finally, we show that a small batch size combined with an optimizer with a small state size can provide the performance benefits of full fine-tuning while maintaining a similar memory footprint to LoRA.
-
 Gemstones: A Model Suite for Scaling LawsSean McLeish , John Kirchenbauer , David Yu Miller , Siddharth Singh , Abhinav Bhatele , Micah Goldblum , Ashwinee Panda , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2025
Gemstones: A Model Suite for Scaling LawsSean McLeish , John Kirchenbauer , David Yu Miller , Siddharth Singh , Abhinav Bhatele , Micah Goldblum , Ashwinee Panda , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2025Scaling laws are typically fit using a family of models with a narrow range of frozen hyper-parameter choices. In this work we study scaling laws using multiple architectural shapes and hyperparameter choices, highlighting their impact on resulting prescriptions. As a primary artifact of our research, we release the Gemstones: an open-source scaling law dataset, consisting of over 4000 checkpoints from transformers with up to 2 billion parameters and diverse architectural shapes; including ablations over learning rate and cooldown. Our checkpoints enable more complex studies of scaling, such as analyzing the relationship between width and depth. By examining our model suite, we find that the prescriptions of scaling laws can be highly sensitive to the experimental design process and the specific model checkpoints used during fitting.
-
 Brain-Predictive Reasoning Embedding through Residual DisentanglementLinyang He , Tianjun Zhong , Richard Antonello , Gavin Mischler , Micah Goldblum , and Nima MesgaraniAdvances in Neural Information Processing Systems (NeurIPS), 2025
Brain-Predictive Reasoning Embedding through Residual DisentanglementLinyang He , Tianjun Zhong , Richard Antonello , Gavin Mischler , Micah Goldblum , and Nima MesgaraniAdvances in Neural Information Processing Systems (NeurIPS), 2025Conventional brain encoding analysis using language models that feeds whole hidden states can be biased toward shallow lexical cues. Here we present a residual-layer disentangling method that extracts four nearly orthogonal vectors from a language model, respectively containing information corresponding to lexicon, syntax, meaning, and reasoning. We first probe the model to locate the layers where each linguistic feature is maximal, then strip lower-level feature incrementally. Applying bootstrap-ridge encoding to natural-speech ECoG yields three insights: 1) Our residual pipeline isolates a reasoning embedding with unique predictive value, possible only because the latest large language models exhibit emergent reasoning behavior. 2) Apparent high-level predictive performance in conventional analyses is largely attributable to recycled shallow information, rather than genuine deep processing. 3) The reasoning embedding reveals distinct spatiotemporal brain activation patterns, including recruitment of frontal and visual regions beyond classical language areas, suggesting a potential neural substrate for high-level reasoning. Together, our approach removes shallow bias, aligns distinct transformer strata with brain hierarchies, and provides the first brain-relevant representation of reasoning.
-
 FineGRAIN: Evaluating Failure Modes of Text-to-Image Models with Vision Language Model JudgesKevin David Hayes , Micah Goldblum , Vikash Sehwag , Gowthami Somepalli , Ashwinee Panda , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2025
FineGRAIN: Evaluating Failure Modes of Text-to-Image Models with Vision Language Model JudgesKevin David Hayes , Micah Goldblum , Vikash Sehwag , Gowthami Somepalli , Ashwinee Panda , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2025Text-to-image (T2I) models are capable of generating visually impressive images, yet they often fail to accurately capture specific attributes in user prompts, such as the correct number of objects with the specified colors. The diversity of such errors underscores the need for a hierarchical evaluation framework that can compare prompt adherence abilities of different image generation models. Simultaneously, benchmarks of vision language models (VLMs) have not kept pace with the complexity of scenes that VLMs are used to annotate. In this work, we propose a structured methodology for jointly evaluating T2I models and VLMs by testing whether VLMs can identify 27 specific failure modes in the images generated by T2I models conditioned on challenging prompts. Our second contribution is a dataset of prompts and images generated by 5 T2I models (Flux, SD3-Medium, SD3-Large, SD3.5- Medium, SD3.5-Large) and the corresponding annotations from a VLM (Molmo) annotated by an LLM (Llama3) to test whether the VLM can correctly identify the failure mode in a generated image. By analyzing failure modes on a curated set of prompts, we reveal systematic errors in attribute fidelity and object representation. Our findings suggest that current metrics are insufficient to capture these nuanced errors, highlighting the importance of targeted benchmarks for advancing generative model reliability and interpretability.
-
 Style Outweighs Substance: Failure Modes of LLM Judges in Alignment BenchmarkingBenjamin Feuer , Micah Goldblum , Teresa Datta , Sanjana Nambiar , Raz Besaleli , Samuel Dooley , Max Cembalest , and John P DickersonInternational Conference on Learning Representations (ICLR), 2025
Style Outweighs Substance: Failure Modes of LLM Judges in Alignment BenchmarkingBenjamin Feuer , Micah Goldblum , Teresa Datta , Sanjana Nambiar , Raz Besaleli , Samuel Dooley , Max Cembalest , and John P DickersonInternational Conference on Learning Representations (ICLR), 2025The release of ChatGPT in November 2022 sparked an explosion of interest in post-training and an avalanche of new preference optimization (PO) methods. These methods claim superior alignment by virtue of better correspondence with human pairwise preferences, often measured by LLM-judges. In this work, we attempt to answer the following question – do LLM-judge preferences translate to progress on other, more concrete metrics for alignment, and if not, why not? We define a concrete metric for alignment, and introduce SOS-Bench (Substance Outweighs Style Benchmark), which is to the best of our knowledge the largest standardized, reproducible LLM meta-benchmark to date. We find that (1) LLM-judge preferences do not correlate with concrete measures of safety, world knowledge, and instruction following; (2) LLM-judges have powerful implicit biases, prioritizing style over factuality and safety; and (3) the supervised fine-tuning (SFT) stage of post-training, and not the PO stage, has the greatest impact on alignment, with data scaling and prompt diversity as the driving factors.
-
 Adaptive Rentention & Correction for Continual LearningHaoran Chen , Micah Goldblum , Zuxuan Wu , and Yu-Gang JiangInternational Conference on Learning Representations (ICLR), 2025
Adaptive Rentention & Correction for Continual LearningHaoran Chen , Micah Goldblum , Zuxuan Wu , and Yu-Gang JiangInternational Conference on Learning Representations (ICLR), 2025Continual learning, also known as lifelong learning or incremental learning, refers to the process by which a model learns from a stream of incoming data over time. A common problem in continual learning is the classification layer’s bias towards the most recent task. Traditionally, methods have relied on incorporating data from past tasks during training to mitigate this issue. However, the recent shift in continual learning to memory-free environments has rendered these approaches infeasible. In this study, we propose a solution focused on the testing phase. We first introduce a simple Out-of-Task Detection method, OTD, designed to accurately identify samples from past tasks during testing. Leveraging OTD, we then propose: (1) an Adaptive Retention mechanism for dynamically tuning the classifier layer on past task data; (2) an Adaptive Correction mechanism for revising predictions when the model classifies data from previous tasks into classes from the current task. We name our approach Adaptive Retention & Correction (ARC). While designed for memory-free environments, ARC also proves effective in memory-based settings. Extensive experiments show that our proposed method can be plugged in to virtually any existing continual learning approach without requiring any modifications to its training procedure. Specifically, when integrated with state-of-the-art approaches, ARC achieves an average performance increase of 2.7% and 2.6% on the CIFAR-100 and Imagenet-R datasets, respectively.
-
 Hidden No More: Attacking and Defending Private Third-Party LLM InferenceRahul Krishna Thomas , Louai Zahran , Erica Choi , Akilesh Potti , Micah Goldblum , and Arka PalInternational Conference on Machine Learning (ICML), 2025
Hidden No More: Attacking and Defending Private Third-Party LLM InferenceRahul Krishna Thomas , Louai Zahran , Erica Choi , Akilesh Potti , Micah Goldblum , and Arka PalInternational Conference on Machine Learning (ICML), 2025Recent advances in Large Language Models (LLMs) have led to widespread adoption of thirdparty inference services, raising critical privacy concerns. In this work, we introduce a novel reconstruction technique that can recover original prompts from hidden states with nearly perfect accuracy across multiple state-of-the-art LLMs in the increasingly important open-weights setting. Although the attack is conceptually simple, it has not– to the best of our knowledge– previously been described nor shown to work practically. Furthermore, our attack remains effective against various permutation and noise-based defenses, challenging assumptions about the security of previously proposed schemes. To address these vulnerabilities, we propose Cascade, a multiparty inference scheme that leverages sharding in the sequence dimension to retain privacy of the user input. Through theoretical analysis and empirical evaluation, we demonstrate that Cascade is secure against both our attack as well as previous methods, while maintaining computational and communication efficiency. Our findings highlight the importance of rigorous security analysis in privacy-preserving LLM inference and offer practical solutions for secure deployment.








2024
-
 The No Free Lunch Theorem, Kolmogorov Complexity, and the Role of Inductive Biases in Machine LearningMicah Goldblum , Marc Finzi , Keefer Rowan , and Andrew Gordon WilsonInternational Conference on Machine Learning (ICML), 2024
The No Free Lunch Theorem, Kolmogorov Complexity, and the Role of Inductive Biases in Machine LearningMicah Goldblum , Marc Finzi , Keefer Rowan , and Andrew Gordon WilsonInternational Conference on Machine Learning (ICML), 2024No free lunch theorems for supervised learning state that no learner can solve all problems or that all learners achieve exactly the same accuracy on average over a uniform distribution on learning problems. Accordingly, these theorems are often referenced in support of the notion that individual problems require specially tailored inductive biases. While virtually all uniformly sampled datasets have high complexity, real-world problems disproportionately generate low-complexity data, and we argue that neural network models share this same preference, formalized using Kolmogorov complexity. Notably, we show that architectures designed for a particular domain, such as computer vision, can compress datasets on a variety of seemingly unrelated domains. Our experiments show that pre-trained and even randomly initialized language models prefer to generate low-complexity sequences. Whereas no free lunch theorems seemingly indicate that individual problems require specialized learners, we explain how tasks that often require human intervention such as picking an appropriately sized model when labeled data is scarce or plentiful can be automated into a single learning algorithm. These observations justify the trend in deep learning of unifying seemingly disparate problems with an increasingly small set of machine learning models.
-
 Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated TextAbhimanyu Hans , Avi Schwarzschild , Valeriia Cherepanova , Hamid Kazemi , Aniruddha Saha , Micah Goldblum , Jonas Geiping , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2024
Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated TextAbhimanyu Hans , Avi Schwarzschild , Valeriia Cherepanova , Hamid Kazemi , Aniruddha Saha , Micah Goldblum , Jonas Geiping , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2024Detecting text generated by modern large language models is thought to be hard, as both LLMs and humans can exhibit a wide range of complex behaviors. However, we find that a score based on contrasting two closely related language models is highly accurate at separating human-generated and machine-generated text. Based on this mechanism, we propose a novel LLM detector that only requires simple calculations using a pair of pre-trained LLMs. The method, called Binoculars, achieves state-of-the-art accuracy without any training data. It is capable of spotting machine text from a range of modern LLMs without any model-specific modifications. We comprehensively evaluate Binoculars on a number of text sources and in varied situations. Over a wide range of document types, Binoculars detects over 90% of generated samples from ChatGPT (and other LLMs) at a false positive rate of 0.01%, despite not being trained on any ChatGPT data.
-
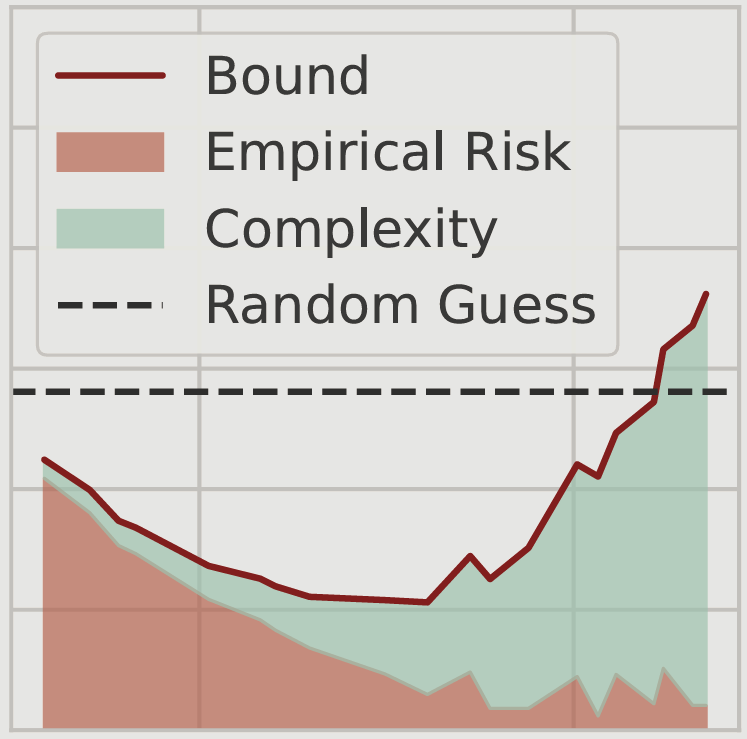 Non-Vacuous Generalization Bounds for Large Language ModelsSanae Lotfi , Marc Finzi , Yilun Kuang , Tim GJ Rudner , Micah Goldblum , and Andrew Gordon WilsonInternational Conference on Machine Learning (ICML), 2024
Non-Vacuous Generalization Bounds for Large Language ModelsSanae Lotfi , Marc Finzi , Yilun Kuang , Tim GJ Rudner , Micah Goldblum , and Andrew Gordon WilsonInternational Conference on Machine Learning (ICML), 2024Modern language models can contain billions of parameters, raising the question of whether they can generalize beyond the training data or simply regurgitate their training corpora. We provide the first non-vacuous generalization bounds for pretrained large language models (LLMs), indicating that language models are capable of discovering regularities that generalize to unseen data. In particular, we derive a compression bound that is valid for the unbounded log-likelihood loss using prediction smoothing, and we extend the bound to handle subsampling, accelerating bound computation on massive datasets. To achieve the extreme level of compression required for non-vacuous generalization bounds, we devise SubLoRA, a low-dimensional non-linear parameterization. Using this approach, we find that larger models have better generalization bounds and are more compressible than smaller models.
-
 Large Language Models Must Be Taught to Know What They Don’t KnowSanyam Kapoor , Nate Gruver , Manley Roberts , Katherine Collins , Arka Pal , Umang Bhatt , Adrian Weller , Samuel Dooley , Micah Goldblum , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2024
Large Language Models Must Be Taught to Know What They Don’t KnowSanyam Kapoor , Nate Gruver , Manley Roberts , Katherine Collins , Arka Pal , Umang Bhatt , Adrian Weller , Samuel Dooley , Micah Goldblum , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2024When using large language models (LLMs) in high-stakes applications, we need to know when we can trust their predictions. Some works argue that prompting high-performance LLMs is sufficient to produce calibrated uncertainties, while others introduce sampling methods that can be prohibitively expensive. In this work, we first argue that prompting on its own is insufficient to achieve good calibration and then show that fine-tuning on a small dataset of correct and incorrect answers can create an uncertainty estimate with good generalization and small computational overhead. We show that a thousand graded examples are sufficient to outperform baseline methods and that training through the features of a model is necessary for good performance and tractable for large open-source models when using LoRA. We also investigate the mechanisms that enable reliable LLM uncertainty estimation, finding that many models can be used as general-purpose uncertainty estimators, applicable not just to their own uncertainties but also the uncertainty of other models. Lastly, we show that uncertainty estimates inform human use of LLMs in human-AI collaborative settings through a user study.
-
 TuneTables: Context Optimization for Scalable Prior-Data Fitted NetworksBenjamin Feuer , Robin Tibor Schirrmeister , Valeriia Cherepanova , Chinmay Hegde , Frank Hutter , Micah Goldblum , Niv Cohen , and Colin WhiteAdvances in Neural Information Processing Systems (NeurIPS), 2024
TuneTables: Context Optimization for Scalable Prior-Data Fitted NetworksBenjamin Feuer , Robin Tibor Schirrmeister , Valeriia Cherepanova , Chinmay Hegde , Frank Hutter , Micah Goldblum , Niv Cohen , and Colin WhiteAdvances in Neural Information Processing Systems (NeurIPS), 2024While tabular classification has traditionally relied on from-scratch training, a recent breakthrough called prior-data fitted networks (PFNs) challenges this approach. Similar to large language models, PFNs make use of pretraining and in-context learning to achieve strong performance on new tasks in a single forward pass. However, current PFNs have limitations that prohibit their widespread adoption. Notably, TabPFN achieves very strong performance on small tabular datasets but is not designed to make predictions for datasets of size larger than 1000. In this work, we overcome these limitations and substantially improve the performance of PFNs by developing context optimization techniques for PFNs. Specifically, we propose TuneTables, a novel prompt-tuning strategy that compresses large datasets into a smaller learned context. TuneTables scales TabPFN to be competitive with state-of-the-art tabular classification methods on larger datasets, while having a substantially lower inference time than TabPFN. Furthermore, we show that TuneTables can be used as an interpretability tool and can even be used to mitigate biases by optimizing a fairness objective.
-
 Unlocking Tokens as Data Points for Generalization Bounds on Larger Language ModelsSanae Lotfi , Yilun Kuang , Brandon Amos , Micah Goldblum , Marc Finzi , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2024
Unlocking Tokens as Data Points for Generalization Bounds on Larger Language ModelsSanae Lotfi , Yilun Kuang , Brandon Amos , Micah Goldblum , Marc Finzi , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2024Large language models (LLMs) with billions of parameters excel at predicting the next token in a sequence. Recent work computes non-vacuous compression-based generalization bounds for LLMs, but these bounds are vacuous for large models at the billion-parameter scale. Moreover, these bounds are obtained through restrictive compression techniques, bounding compressed models that generate low-quality text. Additionally, the tightness of these existing bounds depends on the number of IID documents in a training set rather than the much larger number of non-IID constituent tokens, leaving untapped potential for tighter bounds. In this work, we instead use properties of martingales to derive generalization bounds that benefit from the vast number of tokens in LLM training sets. Since a dataset contains far more tokens than documents, our generalization bounds not only tolerate but actually benefit from far less restrictive compression schemes. With Monarch matrices, Kronecker factorizations, and post-training quantization, we achieve non-vacuous generalization bounds for LLMs as large as LLaMA2-70B. Unlike previous approaches, our work achieves the first non-vacuous bounds for models that are deployed in practice and generate high-quality text.
-
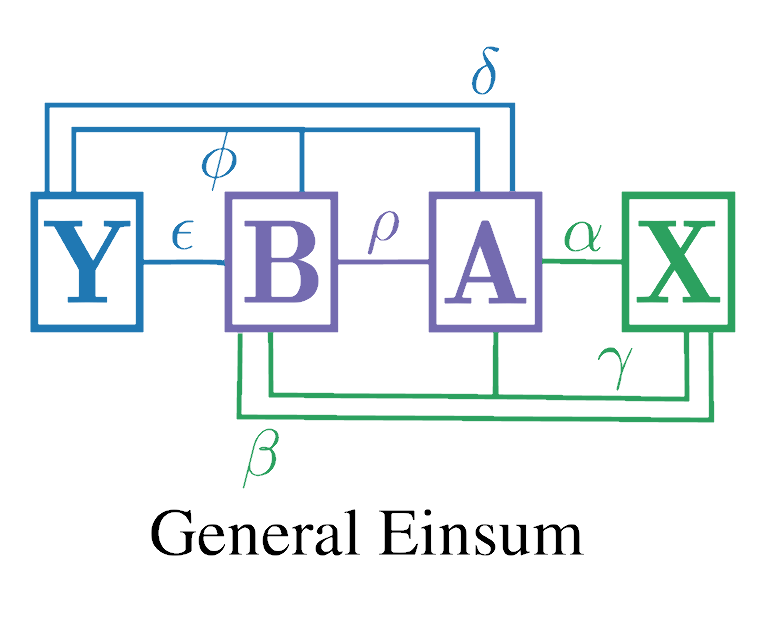 Searching for Efficient Linear Layers over a Continuous Space of Structured MatricesAndres Potapczynski , Shikai Qiu , Marc Anton Finzi , Christopher Ferri , Zixi Chen , Micah Goldblum , Bayan C Bruss , Christopher De Sa , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2024
Searching for Efficient Linear Layers over a Continuous Space of Structured MatricesAndres Potapczynski , Shikai Qiu , Marc Anton Finzi , Christopher Ferri , Zixi Chen , Micah Goldblum , Bayan C Bruss , Christopher De Sa , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2024Dense linear layers are the dominant computational bottleneck in large neural networks, presenting a critical need for more efficient alternatives. Previous efforts to develop alternatives have focused on a small number of hand-crafted structured matrices, and have neglected to investigate whether these structures can surpass dense layers in terms of compute-optimal scaling laws when both the model size and training examples are optimally allocated. In this work, we present a unifying framework that enables searching among all linear operators expressible via an Einstein summation. This framework encompasses many previously proposed structures, such as low-rank, Kronecker, Tensor-Train, and Monarch, along with many novel structures. We develop a taxonomy of all such operators based on their computational and algebraic properties, which provides insights into their scaling laws. Combining these insights with empirical evaluation, we identify a subset of structures that achieve equal or better performance than dense layers as a function of training compute. To further improve their compute efficiency, we develop a natural extension of these performant structures that convert them into a sparse Mixture-of-Experts layer. The resulting layer significantly outperforms dense layers in compute-optimal training efficiency for GPT-2 language models.
-
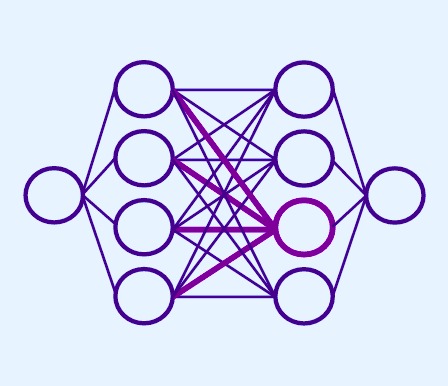 Compute Better Spent: Replacing Dense Layers with Structured MatricesShikai Qiu , Andres Potapczynski , Marc Anton Finzi , Micah Goldblum , and Andrew Gordon WilsonInternational Conference on Machine Learning (ICML), 2024
Compute Better Spent: Replacing Dense Layers with Structured MatricesShikai Qiu , Andres Potapczynski , Marc Anton Finzi , Micah Goldblum , and Andrew Gordon WilsonInternational Conference on Machine Learning (ICML), 2024Dense linear layers are the dominant computational bottleneck in foundation models. Identifying more efficient alternatives to dense matrices has enormous potential for building more compute-efficient models, as exemplified by the success of convolutional networks in the image domain. In this work, we systematically explore structured matrices as replacements for dense matrices. We show that different structures often require drastically different initialization scales and learning rates, which are crucial to performance, especially as models scale. Using insights from the Maximal Update Parameterization, we determine the optimal scaling for initialization and learning rates of these unconventional layers. Finally, we measure the scaling laws of different structures to compare how quickly their performance improves with compute. We propose a novel matrix family containing Monarch matrices, the Block Tensor-Train (BTT), which we show performs better than dense matrices for the same compute on multiple tasks. On CIFAR-10/100 with augmentation, BTT achieves exponentially lower training loss than dense when training MLPs and ViTs. BTT matches dense ViT-S/32 performance on ImageNet-1k with 3.8 times less compute and is more efficient than dense for training small GPT-2 language models.
-
 Measuring Style Similarity in Diffusion ModelsGowthami Somepalli , Anubhav Gupta , Kamal Gupta , Shramay Palta , Micah Goldblum , Jonas Geiping , Abhinav Shrivastava , and Tom GoldsteinEuropean Conference on Computer Vision (ECCV), 2024
Measuring Style Similarity in Diffusion ModelsGowthami Somepalli , Anubhav Gupta , Kamal Gupta , Shramay Palta , Micah Goldblum , Jonas Geiping , Abhinav Shrivastava , and Tom GoldsteinEuropean Conference on Computer Vision (ECCV), 2024Generative models are now widely used by graphic designers and artists. Prior works have shown that these models remember and often replicate content from their training data during generation. Hence as their proliferation increases, it has become important to perform a database search to determine whether the properties of the image are attributable to specific training data, every time before a generated image is used for professional purposes. Existing tools for this purpose focus on retrieving images of similar semantic content. Meanwhile, many artists are concerned with style replication in text-to-image models. We present a framework for understanding and extracting style descriptors from images. Our framework comprises a new dataset curated using the insight that style is a subjective property of an image that captures complex yet meaningful interactions of factors including but not limited to colors, textures, shapes, etc. We also propose a method to extract style descriptors that can be used to attribute style of a generated image to the images used in the training dataset of a text-to-image model. We showcase promising results in various style retrieval tasks. We also quantitatively and qualitatively analyze style attribution and matching in the Stable Diffusion model.
-
 On the Reliability of Watermarks for Large Language ModelsJohn Kirchenbauer , Jonas Geiping , Yuxin Wen , Manli Shu , Khalid Saifullah , Kezhi Kong , Kasun Fernando , Aniruddha Saha , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2024
On the Reliability of Watermarks for Large Language ModelsJohn Kirchenbauer , Jonas Geiping , Yuxin Wen , Manli Shu , Khalid Saifullah , Kezhi Kong , Kasun Fernando , Aniruddha Saha , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2024Large language models (LLMs) are now deployed to everyday use and positioned to produce large quantities of text in the coming decade. Machine-generated text may displace human-written text on the internet and has the potential to be used for malicious purposes, such as spearphishing attacks and social media bots. Watermarking is a simple and effective strategy for mitigating such harms by enabling the detection and documentation of LLM-generated text. Yet, a crucial question remains: How reliable is watermarking in realistic settings in the wild? There, watermarked text might be mixed with other text sources, paraphrased by human writers or other language models, and used for applications in a broad number of domains, both social and technical. In this paper, we explore different detection schemes, quantify their power at detecting watermarks, and determine how much machine-generated text needs to be observed in each scenario to reliably detect the watermark. We especially highlight our human study, where we investigate the reliability of watermarking when faced with human paraphrasing. We compare watermark-based detection to other detection strategies, finding overall that watermarking is a reliable solution, especially because of its sample complexity - for all attacks we consider, the watermark evidence compounds the more examples are given, and the watermark is eventually detected.
-
 NEFTune: Noisy Embeddings Improve Instruction FinetuningNeel Jain , Ping-yeh Chiang , Yuxin Wen , John Kirchenbauer , Hong-Min Chu , Gowthami Somepalli , Brian Bartoldson , Bhavya Kailkhura , Avi Schwarzschild , Aniruddha Saha , Micah Goldblum , Jonas Geiping , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2024
NEFTune: Noisy Embeddings Improve Instruction FinetuningNeel Jain , Ping-yeh Chiang , Yuxin Wen , John Kirchenbauer , Hong-Min Chu , Gowthami Somepalli , Brian Bartoldson , Bhavya Kailkhura , Avi Schwarzschild , Aniruddha Saha , Micah Goldblum , Jonas Geiping , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2024We show that language model finetuning can be improved, sometimes dramatically, with a simple augmentation. NEFTune adds noise to the embedding vectors during training. Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
-
 Universal guidance for diffusion modelsArpit Bansal , Hong-Min Chu , Avi Schwarzschild , Soumyadip Sengupta , Micah Goldblum , Jonas Geiping , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2024
Universal guidance for diffusion modelsArpit Bansal , Hong-Min Chu , Avi Schwarzschild , Soumyadip Sengupta , Micah Goldblum , Jonas Geiping , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2024Typical diffusion models are trained to accept a particular form of conditioning, most commonly text, and cannot be conditioned on other modalities without retraining. In this work, we propose a universal guidance algorithm that enables diffusion models to be controlled by arbitrary guidance modalities without the need to retrain any use-specific components. We show that our algorithm successfully generates quality images with guidance functions including segmentation, face recognition, object detection, and classifier signals.












2023
-
 Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision TasksMicah Goldblum , Hossein Souri , Renkun Ni , Manli Shu , Viraj Uday Prabhu , Gowthami Somepalli , Prithvijit Chattopadhyay , Adrien Bardes , Mark Ibrahim , Judy Hoffman , Rama Chellappa , Andrew Gordon Wilson , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2023
Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision TasksMicah Goldblum , Hossein Souri , Renkun Ni , Manli Shu , Viraj Uday Prabhu , Gowthami Somepalli , Prithvijit Chattopadhyay , Adrien Bardes , Mark Ibrahim , Judy Hoffman , Rama Chellappa , Andrew Gordon Wilson , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2023Neural network based computer vision systems are typically built on a backbone, a pretrained or randomly initialized feature extractor. Several years ago, the default option was an ImageNet-trained convolutional neural network. However, the recent past has seen the emergence of countless backbones pretrained using various algorithms and datasets. While this abundance of choice has led to performance increases for a range of systems, it is difficult for practitioners to make informed decisions about which backbone to choose. Battle of the Backbones (BoB) makes this choice easier by benchmarking a diverse suite of pretrained models, including vision-language models, those trained via self-supervised learning, and the Stable Diffusion backbone, across a diverse set of computer vision tasks ranging from classification to object detection to OOD generalization and more. Furthermore, BoB sheds light on promising directions for the research community to advance computer vision by illuminating strengths and weakness of existing approaches through a comprehensive analysis conducted on more than 1500 training runs. While vision transformers (ViTs) and self-supervised learning (SSL) are increasingly popular, we find that convolutional neural networks pretrained in a supervised fashion on large training sets still perform best on most tasks among the models we consider. Moreover, in apples-to-apples comparisons on the same architectures and similarly sized pretraining datasets, we find that SSL backbones are highly competitive, indicating that future works should perform SSL pretraining with advanced architectures and larger pretraining datasets.
-
 Rethinking Bias Mitigation: Fairer Architectures Make for Fairer Face RecognitionSamuel Dooley , Rhea Sukthanker , John P Dickerson , Colin White , Frank Hutter , and Micah GoldblumAdvances in Neural Information Processing Systems (NeurIPS), 2023
Rethinking Bias Mitigation: Fairer Architectures Make for Fairer Face RecognitionSamuel Dooley , Rhea Sukthanker , John P Dickerson , Colin White , Frank Hutter , and Micah GoldblumAdvances in Neural Information Processing Systems (NeurIPS), 2023Face recognition systems are widely deployed in safety-critical applications, including law enforcement, yet they exhibit bias across a range of socio-demographic dimensions, such as gender and race. Conventional wisdom dictates that model biases arise from biased training data. As a consequence, previous works on bias mitigation largely focused on pre-processing the training data, adding penalties to prevent bias from effecting the model during training, or post-processing predictions to debias them, yet these approaches have shown limited success on hard problems such as face recognition. In our work, we discover that biases are actually inherent to neural network architectures themselves. Following this reframing, we conduct the first neural architecture search for fairness, jointly with a search for hyperparameters. Our search outputs a suite of models which Pareto-dominate all other high-performance architectures and existing bias mitigation methods in terms of accuracy and fairness, often by large margins, on the two most widely used datasets for face identification, CelebA and VGGFace2. Furthermore, these models generalize to other datasets and sensitive attributes.
-
 A Performance-Driven Benchmark for Feature Selection in Tabular Deep LearningValeriia Cherepanova , Gowthami Somepalli , Jonas Geiping , C. Bayan Bruss , Andrew Gordon Wilson , Tom Goldstein , and Micah GoldblumAdvances in Neural Information Processing Systems (NeurIPS), 2023
A Performance-Driven Benchmark for Feature Selection in Tabular Deep LearningValeriia Cherepanova , Gowthami Somepalli , Jonas Geiping , C. Bayan Bruss , Andrew Gordon Wilson , Tom Goldstein , and Micah GoldblumAdvances in Neural Information Processing Systems (NeurIPS), 2023Academic tabular benchmarks often contain small sets of curated features. In contrast, data scientists typically collect as many features as possible into their datasets, and even engineer new features from existing ones. To prevent over-fitting in subsequent downstream modeling, practitioners commonly use automated feature selection methods that identify a reduced subset of informative features. Existing benchmarks for tabular feature selection consider classical downstream models, toy synthetic datasets, or do not evaluate feature selectors on the basis of downstream performance. We construct a challenging feature selection benchmark evaluated on downstream neural networks including transformers, using real datasets and multiple methods for generating extraneous features. We also propose an input-gradient-based analogue of LASSO for neural networks that outperforms classical feature selection methods on challenging problems such as selecting from corrupted or second-order features.
-
 Simplifying Neural Network Training Under Class ImbalanceRavid Shwartz-Ziv , Micah Goldblum , Yucen Lily Li , C. Bayan Bruss , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2023
Simplifying Neural Network Training Under Class ImbalanceRavid Shwartz-Ziv , Micah Goldblum , Yucen Lily Li , C. Bayan Bruss , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2023Real-world datasets are often highly class-imbalanced, which can adversely impact the performance of deep learning models. The majority of research on training neural networks under class imbalance has focused on specialized loss functions and sampling techniques. Notably, we demonstrate that simply tuning existing components of standard deep learning pipelines, such as the batch size, data augmentation, architecture size, pre-training, optimizer, and label smoothing, can achieve state-of-the-art performance without any specialized loss functions or samplers. We also provide key prescriptions and considerations for training under class imbalance, and an understanding of why imbalance methods succeed or fail.
-
 Cold Diffusion: Inverting Arbitrary Image Transforms Without NoiseArpit Bansal , Eitan Borgnia , Hong-Min Chu , Jie S Li , Hamid Kazemi , Furong Huang , Micah Goldblum , Jonas Geiping , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2023
Cold Diffusion: Inverting Arbitrary Image Transforms Without NoiseArpit Bansal , Eitan Borgnia , Hong-Min Chu , Jie S Li , Hamid Kazemi , Furong Huang , Micah Goldblum , Jonas Geiping , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2023Standard diffusion models involve an image transform – adding Gaussian noise – and an image restoration operator that inverts this degradation. We observe that the generative behavior of diffusion models is not strongly dependent on the choice of image degradation, and in fact an entire family of generative models can be constructed by varying this choice. Even when using completely deterministic degradations (e.g., blur, masking, and more), the training and test-time update rules that underlie diffusion models can be easily generalized to create generative models. The success of these fully deterministic models calls into question the community’s understanding of diffusion models, which relies on noise in either gradient Langevin dynamics or variational inference, and paves the way for generalized diffusion models that invert arbitrary processes.
-
 Why Diffusion Models Memorize and How to Mitigate CopyingGowthami Somepalli , Vasu Singla , Micah Goldblum , Jonas Geiping , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2023
Why Diffusion Models Memorize and How to Mitigate CopyingGowthami Somepalli , Vasu Singla , Micah Goldblum , Jonas Geiping , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2023Images generated by diffusion models like Stable Diffusion are increasingly widespread. Recent works and even lawsuits have shown that these models are prone to replicating their training data, unbeknownst to the user. In this paper, we first analyze this memorization problem in text-to-image diffusion models. While it is widely believed that duplicated images in the training set are responsible for content replication at inference time, we observe that the text conditioning of the model plays a similarly important role. In fact, we see in our experiments that data replication often does not happen for unconditional models, while it is common in the text-conditional case. Motivated by our findings, we then propose several techniques for reducing data replication at inference time by randomizing and augmenting image captions in the training set.
-
 Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and DiscoveryYuxin Wen , Neel Jain , John Kirchenbauer , Micah Goldblum , Jonas Geiping , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2023
Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and DiscoveryYuxin Wen , Neel Jain , John Kirchenbauer , Micah Goldblum , Jonas Geiping , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2023The strength of modern generative models lies in their ability to be controlled through text-based prompts. Typical "hard" prompts are made from interpretable words and tokens, and must be hand-crafted by humans. There are also "soft" prompts, which consist of continuous feature vectors. These can be discovered using powerful optimization methods, but they cannot be easily interpreted, re-used across models, or plugged into a text-based interface. We describe an approach to robustly optimize hard text prompts through efficient gradient-based optimization. Our approach automatically generates hard text-based prompts for both text-to-image and text-to-text applications. In the text-to-image setting, the method creates hard prompts for diffusion models, allowing API users to easily generate, discover, and mix and match image concepts without prior knowledge on how to prompt the model. In the text-to-text setting, we show that hard prompts can be automatically discovered that are effective in tuning LMs for classification.
-
 When Do Neural Nets Outperform Boosted Trees on Tabular Data?Duncan McElfresh , Sujay Khandagale , Jonathan Valverde , Ganesh Ramakrishnan , Micah Goldblum , Colin White , and othersAdvances in Neural Information Processing Systems (NeurIPS), 2023
When Do Neural Nets Outperform Boosted Trees on Tabular Data?Duncan McElfresh , Sujay Khandagale , Jonathan Valverde , Ganesh Ramakrishnan , Micah Goldblum , Colin White , and othersAdvances in Neural Information Processing Systems (NeurIPS), 2023Tabular data is one of the most commonly used types of data in machine learning. Despite recent advances in neural nets (NNs) for tabular data, there is still an active discussion on whether or not NNs generally outperform gradient-boosted decision trees (GBDTs) on tabular data, with several recent works arguing either that GBDTs consistently outperform NNs on tabular data, or vice versa. In this work, we take a step back and ask, ’does it matter?’ We conduct the largest tabular data analysis to date, by comparing 19 algorithms across 176 datasets, and we find that the ’NN vs. GBDT’ debate is overemphasized: for a surprisingly high number of datasets, either the performance difference between GBDTs and NNs is negligible, or light hyperparameter tuning on a GBDT is more important than selecting the best algorithm. Next, we analyze 965 metafeatures to determine what properties of a dataset make NNs or GBDTs better-suited to perform well. For example, we find that GBDTs are much better than NNs at handling skewed feature distributions, heavy-tailed feature distributions, and other forms of dataset irregularities. Our insights act as a guide for practitioners to decide whether or not they need to run a neural net to reach top performance on their dataset.
-
 What Can We Learn from Unlearnable DatasetsPedro Sandoval-Segura , Vasu Singla , Jonas Geiping , Micah Goldblum , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2023
What Can We Learn from Unlearnable DatasetsPedro Sandoval-Segura , Vasu Singla , Jonas Geiping , Micah Goldblum , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2023In an era of widespread web scraping, unlearnable dataset methods have the potential to protect data privacy by preventing deep neural networks from generalizing. But in addition to a number of practical limitations that make their use unlikely, we make a number of findings that call into question their ability to safeguard data. First, it is widely believed that neural networks trained on unlearnable datasets only learn shortcuts, simpler rules that are not useful for generalization. In contrast, we find that networks actually can learn useful features that can be reweighed for high test performance, suggesting that image privacy is not preserved. Unlearnable datasets are also believed to induce learning shortcuts through linear separability of added perturbations. We provide a counterexample, demonstrating that linear separability of perturbations is not a necessary condition. To emphasize why linearly separable perturbations should not be relied upon, we propose an orthogonal projection attack which allows learning from unlearnable datasets published in ICML 2021 and ICLR 2023. Our proposed attack is significantly less complex than recently proposed techniques.
-
 Transfer Learning with Deep Tabular ModelsRoman Levin , Valeriia Cherepanova , Avi Schwarzschild , Arpit Bansal , Bayan Bruss , Tom Goldstein , Andrew Gordon Wilson , and Micah GoldblumInternational Conference on Learning Representations (ICLR), 2023
Transfer Learning with Deep Tabular ModelsRoman Levin , Valeriia Cherepanova , Avi Schwarzschild , Arpit Bansal , Bayan Bruss , Tom Goldstein , Andrew Gordon Wilson , and Micah GoldblumInternational Conference on Learning Representations (ICLR), 2023Recent work on deep learning for tabular data demonstrates the strong performance of deep tabular models, often bridging the gap between gradient boosted decision trees and neural networks. Accuracy aside, a major advantage of neural models is that they are easily fine-tuned in new domains and learn reusable features. This property is often exploited in computer vision and natural language applications, where transfer learning is indispensable when task-specific training data is scarce. In this work, we explore the benefits that representation learning provides for knowledge transfer in the tabular domain. We conduct experiments in a realistic medical diagnosis test bed with limited amounts of downstream data and find that transfer learning with deep tabular models provides a definitive advantage over gradient boosted decision tree methods. We further compare the supervised and self-supervised pretraining strategies and provide practical advice on transfer learning with tabular models. Finally, we propose a pseudo-feature method for cases where the upstream and downstream feature sets differ, a tabular-specific problem widespread in real-world applications.
-
 Gradient-Based Optimization Is Not Necessary for Generalization in Neural NetworksPing-yeh Chiang , Renkun Ni , David Yu Miller , Arpit Bansal , Jonas Geiping , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2023
Gradient-Based Optimization Is Not Necessary for Generalization in Neural NetworksPing-yeh Chiang , Renkun Ni , David Yu Miller , Arpit Bansal , Jonas Geiping , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2023It is commonly believed that the implicit regularization of optimizers is needed for neural networks to generalize in the overparameterized regime. In this paper, we observe experimentally that this implicit regularization behavior is \em generic, i.e. it does not depend strongly on the choice of optimizer. We demonstrate this by training neural networks using several gradient-free optimizers that do not benefit from properties that are often attributed to gradient-based optimizers. This includes a guess-and-check optimizer that generates uniformly random parameter vectors until one is found that happens to achieve perfect train accuracy, and a zeroth-order pattern search optimizer that uses no gradient computations. In the low sample and few-shot regimes, where zeroth order optimizers are most tractable, we find that these non-gradient optimizers achieve test accuracy comparable to SGD.
-
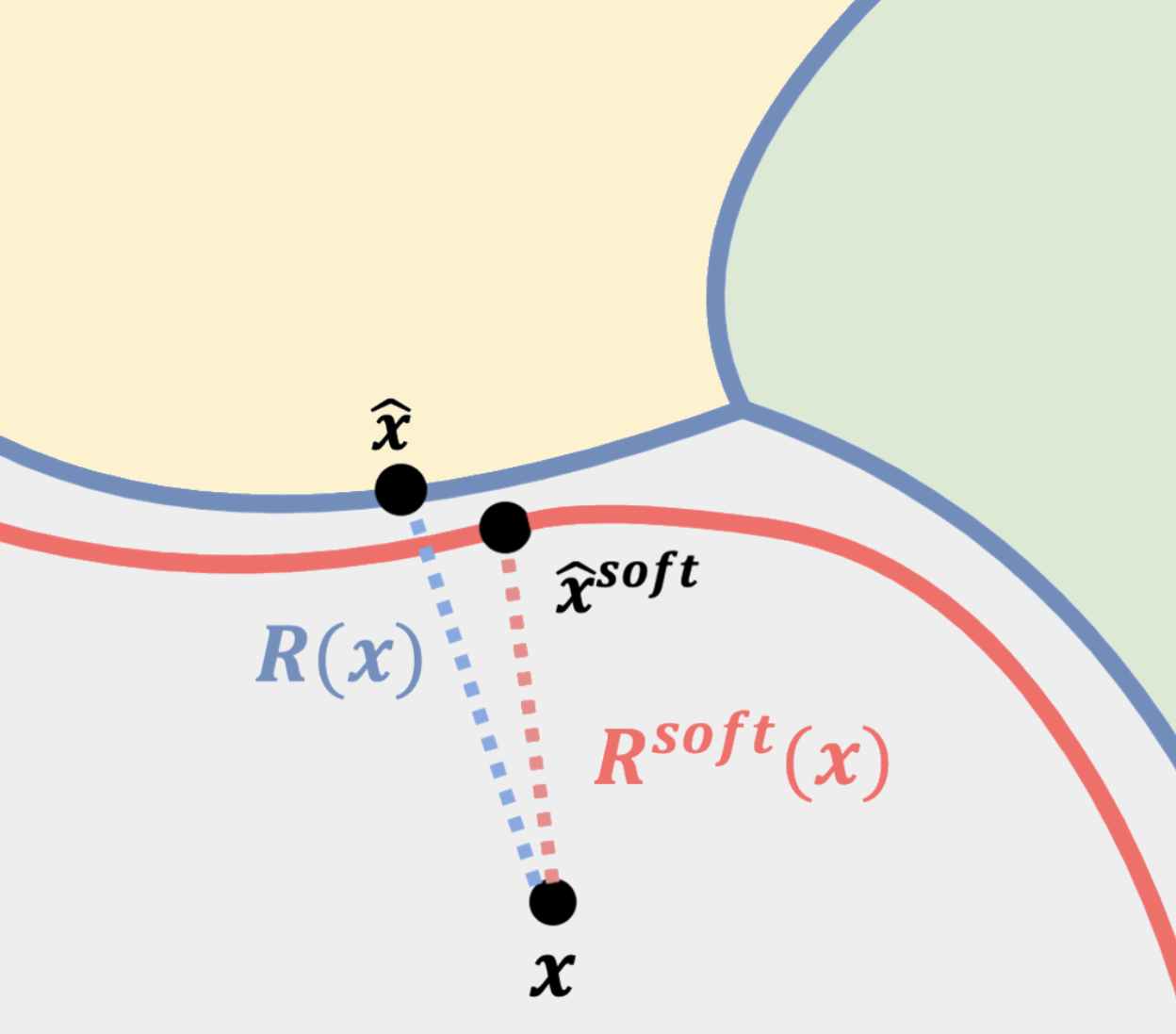 Exploring and Exploiting Decision Boundary Dynamics for Adversarial RobustnessYuancheng Xu , Yanchao Sun , Micah Goldblum , Tom Goldstein , and Furong HuangInternational Conference on Learning Representations (ICLR), 2023
Exploring and Exploiting Decision Boundary Dynamics for Adversarial RobustnessYuancheng Xu , Yanchao Sun , Micah Goldblum , Tom Goldstein , and Furong HuangInternational Conference on Learning Representations (ICLR), 2023The robustness of a deep classifier can be characterized by its margins: the decision boundary’s distances to natural data points. However, it is unclear whether existing robust training methods effectively increase the margin for each vulnerable point during training. To understand this, we propose a continuous-time framework for quantifying the relative speed of the decision boundary with respect to each individual point. Through visualizing the moving speed of the decision boundary under Adversarial Training, one of the most effective robust training algorithms, a surprising moving-behavior is revealed: the decision boundary moves away from some vulnerable points but simultaneously moves closer to others, decreasing their margins. To alleviate these conflicting dynamics of the decision boundary, we propose Dynamics-aware Robust Training (DyART), which encourages the decision boundary to engage in movement that prioritizes increasing smaller margins. In contrast to prior works, DyART directly operates on the margins rather than their indirect approximations, allowing for more targeted and effective robustness improvement. Experiments on the CIFAR-10 and Tiny-ImageNet datasets verify that DyART alleviates the conflicting dynamics of the decision boundary and obtains improved robustness under various perturbation sizes compared to the state-of-the-art defenses. Our code is available at https://github.com/Yuancheng-Xu/Dynamics-Aware-Robust-Training.
-
 Canary in a Coalmine: Better Membership Inference with Ensembled Adversarial QueriesYuxin Wen , Arpit Bansal , Hamid Kazemi , Eitan Borgnia , Micah Goldblum , Jonas Geiping , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2023
Canary in a Coalmine: Better Membership Inference with Ensembled Adversarial QueriesYuxin Wen , Arpit Bansal , Hamid Kazemi , Eitan Borgnia , Micah Goldblum , Jonas Geiping , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2023As industrial applications are increasingly automated by machine learning models, enforcing personal data ownership and intellectual property rights requires tracing training data back to their rightful owners. Membership inference algorithms approach this problem by using statistical techniques to discern whether a target sample was included in a model’s training set. However, existing methods only utilize the unaltered target sample or simple augmentations of the target to compute statistics. Such a sparse sampling of the model’s behavior carries little information, leading to poor inference capabilities. In this work, we use adversarial tools to directly optimize for queries that are discriminative and diverse. Our improvements achieve significantly more accurate membership inference than existing methods, especially in offline scenarios and in the low false-positive regime which is critical in legal settings.
-
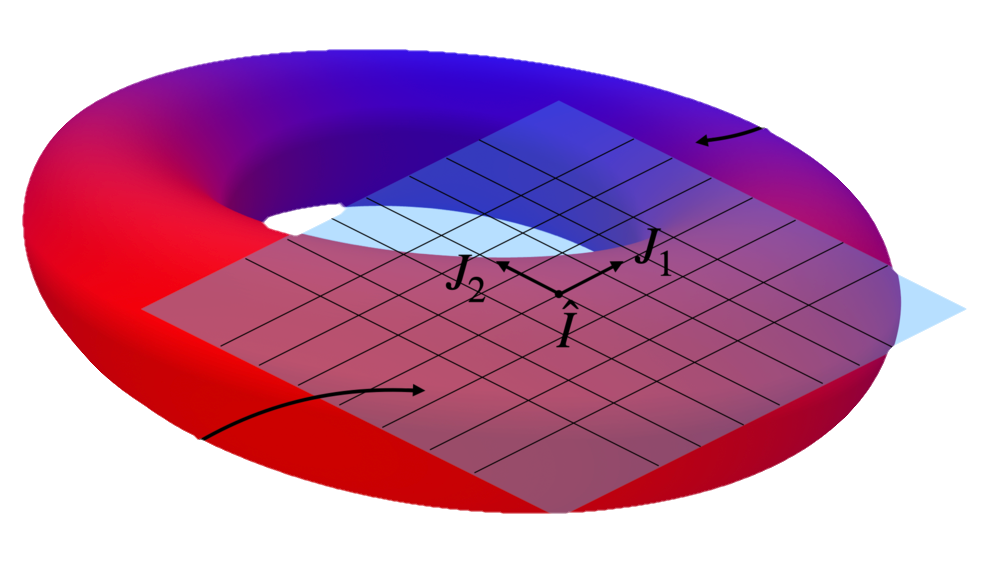 The Lie Derivative for Measuring Learned EquivarianceNate Gruver , Marc Anton Finzi , Micah Goldblum , and Andrew Gordon WilsonInternational Conference on Learning Representations (ICLR), 2023
The Lie Derivative for Measuring Learned EquivarianceNate Gruver , Marc Anton Finzi , Micah Goldblum , and Andrew Gordon WilsonInternational Conference on Learning Representations (ICLR), 2023Equivariance guarantees that a model’s predictions capture key symmetries in data. When an image is translated or rotated, an equivariant model’s representation of that image will translate or rotate accordingly. The success of convolutional neural networks has historically been tied to their ability to directly encode translation equivariance in their architecture. The rising success of vision transformers, which have no explicit architectural bias towards equivariance, challenges this narrative and suggests that augmentations and training data might also play a significant role in their performance. In order to better understand the role of equivariance in recent vision models, we introduce the Lie derivative, a method for measuring equivariance with strong mathematical foundations and minimal hyperparameters. Using the Lie derivative, we study the equivariance properties of hundreds of pretrained models, spanning CNNs, transformers, and Mixer architectures. The scale of our analysis allows us to separate the impact of architecture from other factors like model size or training method. Surprisingly, we find that many violations of equivariance can be linked to spatial aliasing in ubiquitous network layers, such as pointwise non-linearities, and that as models get larger and more accurate they tend to display more equivariance, regardless of architecture.
-
 Panning for Gold in Federated Learning: Targeted Text Extraction under Arbitrarily Large-Scale AggregationHong-Min Chu , Jonas Geiping , Liam H Fowl , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2023
Panning for Gold in Federated Learning: Targeted Text Extraction under Arbitrarily Large-Scale AggregationHong-Min Chu , Jonas Geiping , Liam H Fowl , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2023As federated learning (FL) matures, privacy attacks against FL systems in turn become more numerous and complex. Attacks on language models have progressed from recovering single sentences in simple classification tasks to recovering larger parts of user data. Current attacks against federated language models are sequence-agnostic and aim to extract as much data as possible from an FL update - often at the expense of fidelity for any particular sequence. Because of this, current attacks fail to extract any meaningful data under large-scale aggregation. In realistic settings, an attacker cares most about a small portion of user data that contains sensitive personal information, for example sequences containing the phrase "my credit card number is ...". In this work, we propose the first attack on FL that achieves targeted extraction of sequences that contain privacy-critical phrases, whereby we employ maliciously modified parameters to allow the transformer itself to filter relevant sequences from aggregated user data and encode them in the gradient update. Our attack can effectively extract sequences of interest even against extremely large-scale aggregation.
-
 How Much Data Are Augmentations Worth? An Investigation into Scaling Laws, Invariance, and Implicit RegularizationJonas Geiping , Micah Goldblum , Gowthami Somepalli , Ravid Shwartz-Ziv , Tom Goldstein , and Andrew Gordon WilsonInternational Conference on Learning Representations (ICLR), 2023
How Much Data Are Augmentations Worth? An Investigation into Scaling Laws, Invariance, and Implicit RegularizationJonas Geiping , Micah Goldblum , Gowthami Somepalli , Ravid Shwartz-Ziv , Tom Goldstein , and Andrew Gordon WilsonInternational Conference on Learning Representations (ICLR), 2023Despite the clear performance benefits of data augmentations, little is known about why they are so effective. In this paper, we disentangle several key mechanisms through which data augmentations operate. Establishing an exchange rate between augmented and additional real data, we find that in out-of-distribution testing scenarios, augmentations which yield samples that are diverse, but inconsistent with the data distribution can be even more valuable than additional training data. Moreover, we find that data augmentations which encourage invariances can be more valuable than invariance alone, especially on small and medium sized training sets. Following this observation, we show that augmentations induce additional stochasticity during training, effectively flattening the loss landscape.
-
 Decepticons: Corrupted Transformers Breach Privacy in Federated Learning for Language ModelsLiam H Fowl , Jonas Geiping , Steven Reich , Yuxin Wen , Wojciech Czaja , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2023
Decepticons: Corrupted Transformers Breach Privacy in Federated Learning for Language ModelsLiam H Fowl , Jonas Geiping , Steven Reich , Yuxin Wen , Wojciech Czaja , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2023A central tenet of Federated learning (FL), which trains models without centralizing user data, is privacy. However, previous work has shown that the gradient updates used in FL can leak user information. While the most industrial uses of FL are for text applications (e.g. keystroke prediction), nearly all attacks on FL privacy have focused on simple image classifiers. We propose a novel attack that reveals private user text by deploying malicious parameter vectors, and which succeeds even with mini-batches, multiple users, and long sequences. Unlike previous attacks on FL, the attack exploits characteristics of both the Transformer architecture and the token embedding, separately extracting tokens and positional embeddings to retrieve high-fidelity text. This work suggests that FL on text, which has historically been resistant to privacy attacks, is far more vulnerable than previously thought.
-
 Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion ModelsGowthami Somepalli , Vasu Singla , Micah Goldblum , Jonas Geiping , and Tom GoldsteinComputer Vision and Pattern Recognition Conference (CVPR), 2023
Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion ModelsGowthami Somepalli , Vasu Singla , Micah Goldblum , Jonas Geiping , and Tom GoldsteinComputer Vision and Pattern Recognition Conference (CVPR), 2023Cutting-edge diffusion models produce images with high quality and customizability, enabling them to be used for commercial art and graphic design purposes. But do diffusion models create unique works of art, or are they replicating content directly from their training sets? In this work, we study image retrieval frameworks that enable us to compare generated images with training samples and detect when content has been replicated. Applying our frameworks to diffusion models trained on multiple datasets including Oxford flowers, Celeb-A, ImageNet, and LAION, we discuss how factors such as training set size impact rates of content replication. We also identify cases where diffusion models, including the popular Stable Diffusion model, blatantly copy from their training data.
-
 A cookbook of self-supervised learningRandall Balestriero , Mark Ibrahim , Vlad Sobal , Ari Morcos , Shashank Shekhar , Tom Goldstein , Florian Bordes , Adrien Bardes , Gregoire Mialon , Yuandong Tian , Avi Schwarzschild , Andrew Wilson , Jonas Geiping , Quentin Garrido , Pierre Fernandez , Amir Bar , Hamed Pirsiavash , Yann LeCun , and Micah GoldblumPreprint, 2023
A cookbook of self-supervised learningRandall Balestriero , Mark Ibrahim , Vlad Sobal , Ari Morcos , Shashank Shekhar , Tom Goldstein , Florian Bordes , Adrien Bardes , Gregoire Mialon , Yuandong Tian , Avi Schwarzschild , Andrew Wilson , Jonas Geiping , Quentin Garrido , Pierre Fernandez , Amir Bar , Hamed Pirsiavash , Yann LeCun , and Micah GoldblumPreprint, 2023Cutting-edge diffusion models produce images with high quality and customizability, enabling them to be used for commercial art and graphic design purposes. But do diffusion models create unique works of art, or are they replicating content directly from their training sets? In this work, we study image retrieval frameworks that enable us to compare generated images with training samples and detect when content has been replicated. Applying our frameworks to diffusion models trained on multiple datasets including Oxford flowers, Celeb-A, ImageNet, and LAION, we discuss how factors such as training set size impact rates of content replication. We also identify cases where diffusion models, including the popular Stable Diffusion model, blatantly copy from their training data.



















2022
-
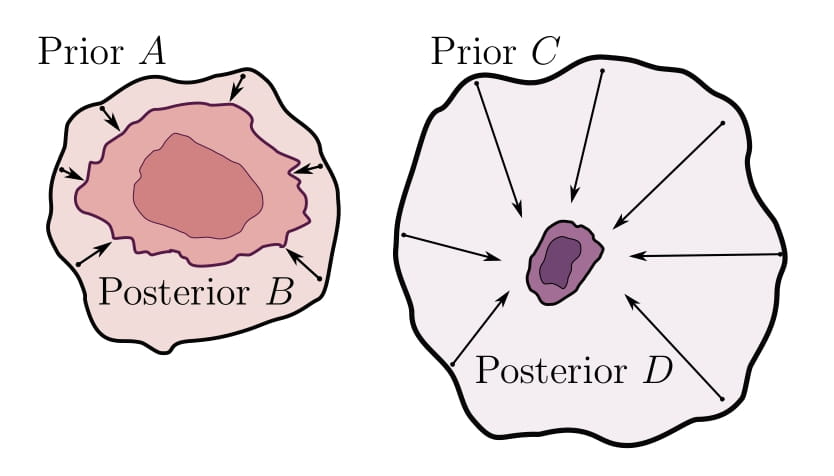 Bayesian Model Selection, the Marginal Likelihood, and GeneralizationSanae Lotfi , Pavel Izmailov , Gregory Benton , Micah Goldblum , and Andrew Gordon WilsonInternational Conference on Machine Learning (ICML) Outstanding Paper Award, 2022
Bayesian Model Selection, the Marginal Likelihood, and GeneralizationSanae Lotfi , Pavel Izmailov , Gregory Benton , Micah Goldblum , and Andrew Gordon WilsonInternational Conference on Machine Learning (ICML) Outstanding Paper Award, 2022How do we compare between hypotheses that are entirely consistent with observations? The marginal likelihood (aka Bayesian evidence), which represents the probability of generating our observations from a prior, provides a distinctive approach to this foundational question, automatically encoding Occam’s razor. Although it has been observed that the marginal likelihood can overfit and is sensitive to prior assumptions, its limitations for hyperparameter learning and discrete model comparison have not been thoroughly investigated. We first revisit the appealing properties of the marginal likelihood for learning constraints and hypothesis testing. We then highlight the conceptual and practical issues in using the marginal likelihood as a proxy for generalization. Namely, we show how marginal likelihood can be negatively correlated with generalization, with implications for neural architecture search, and can lead to both underfitting and overfitting in hyperparameter learning. We provide a partial remedy through a conditional marginal likelihood, which we show is more aligned with generalization, and practically valuable for large-scale hyperparameter learning, such as in deep kernel learning.
-
 Dataset Security for Machine Learning: Data Poisoning, Backdoor Attacks, and DefensesMicah Goldblum , Dimitris Tsipras , Chulin Xie , Xinyun Chen , Avi Schwarzschild , Dawn Song , Aleksander Madry , Bo Li , and Tom GoldsteinIEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022
Dataset Security for Machine Learning: Data Poisoning, Backdoor Attacks, and DefensesMicah Goldblum , Dimitris Tsipras , Chulin Xie , Xinyun Chen , Avi Schwarzschild , Dawn Song , Aleksander Madry , Bo Li , and Tom GoldsteinIEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022As machine learning systems grow in scale, so do their training data requirements, forcing practitioners to automate and outsource the curation of training data in order to achieve state-of-the-art performance. The absence of trustworthy human supervision over the data collection process exposes organizations to security vulnerabilities; training data can be manipulated to control and degrade the downstream behaviors of learned models. The goal of this work is to systematically categorize and discuss a wide range of dataset vulnerabilities and exploits, approaches for defending against these threats, and an array of open problems in this space. In addition to describing various poisoning and backdoor threat models and the relationships among them, we develop their unified taxonomy.
-
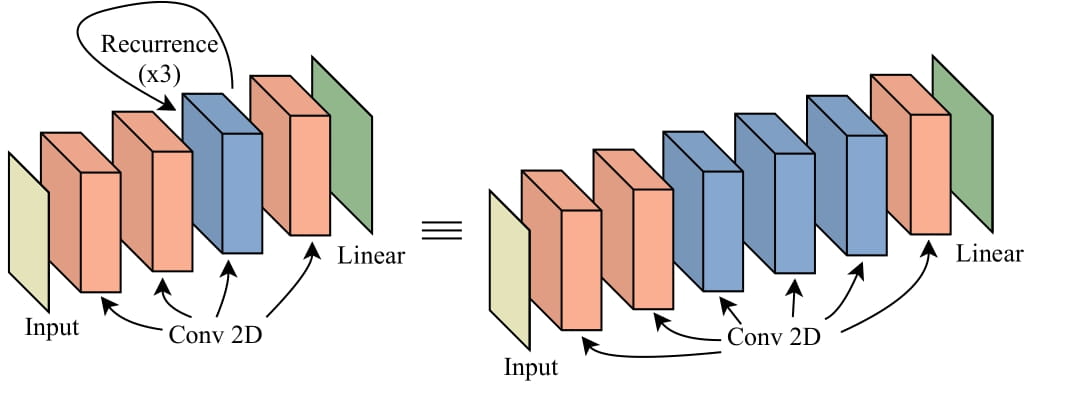 The Uncanny Similarity of Recurrence and DepthAvi Schwarzschild , Arjun Gupta , Amin Ghiasi , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2022
The Uncanny Similarity of Recurrence and DepthAvi Schwarzschild , Arjun Gupta , Amin Ghiasi , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2022It is widely believed that deep neural networks contain layer specialization, wherein networks extract hierarchical features representing edges and patterns in shallow layers and complete objects in deeper layers. Unlike common feed-forward models that have distinct filters at each layer, recurrent networks reuse the same parameters at various depths. In this work, we observe that recurrent models exhibit the same hierarchical behaviors and the same performance benefits as depth despite reusing the same filters at every recurrence. By training models of various feed-forward and recurrent architectures on several datasets for image classification as well as maze solving, we show that recurrent networks have the ability to closely emulate the behavior of non-recurrent deep models, often doing so with far fewer parameters.
-
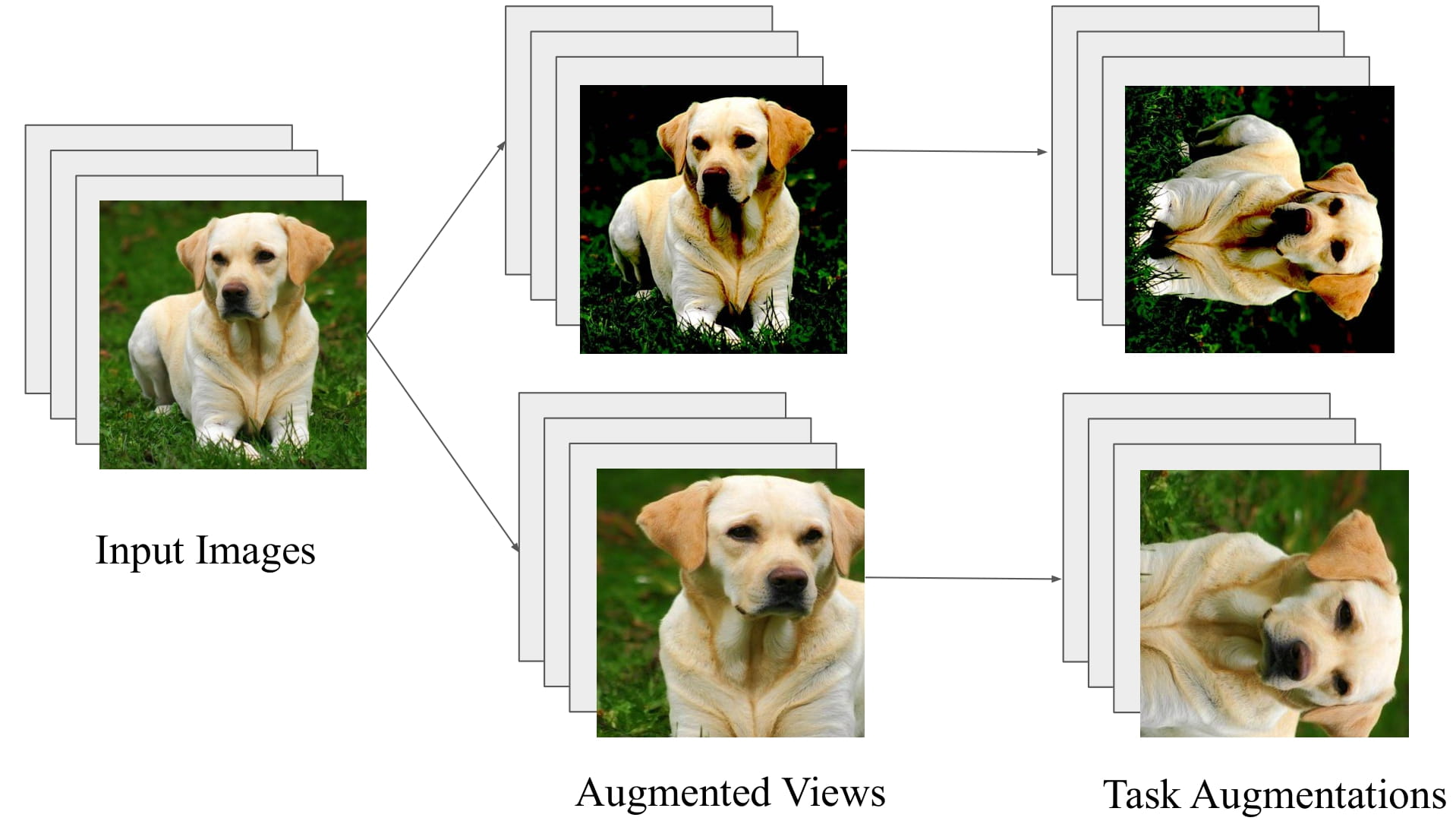 The Close Relationship Between Contrastive Learning and Meta-LearningRenkun Ni , Manli Shu , Hossein Souri , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2022
The Close Relationship Between Contrastive Learning and Meta-LearningRenkun Ni , Manli Shu , Hossein Souri , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2022Contrastive learning has recently taken off as a paradigm for learning from unlabeled data. In this paper, we discuss the close relationship between contrastive learning and meta-learning, and in fact show that contrastive learning can be interpreted as a special case of meta-learning with a certain task distribution. We complement this observation by showing that established meta-learning methods, such as Prototypical Networks, achieve comparable performance to SimCLR when paired with this task distribution. This close relationship can be leveraged by taking established techniques from the meta-learning literature, such as task-based data augmentation, and showing that they benefit contrastive learning as well. These tricks also benefit state-of-the-art self-supervised learners without using negative pairs such as BYOL, which achieves 94.6% accuracy on CIFAR-10 using a self-supervised ResNet-18 feature extractor trained with our meta-learning tricks.
-
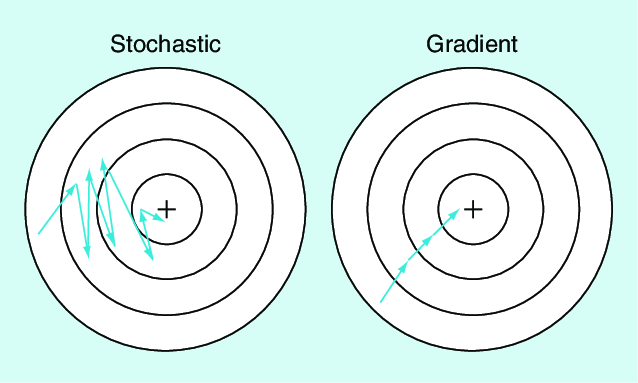 Stochastic Training is Not Necessary for GeneralizationJonas Geiping , Micah Goldblum , Phil Pope , Michael Moeller , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2022
Stochastic Training is Not Necessary for GeneralizationJonas Geiping , Micah Goldblum , Phil Pope , Michael Moeller , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2022It is widely believed that the implicit regularization of SGD is fundamental to the impressive generalization behavior we observe in neural networks. In this work, we demonstrate that non-stochastic full-batch training can achieve comparably strong performance to SGD on CIFAR-10 using modern architectures. To this end, we show that the implicit regularization of SGD can be completely replaced with explicit regularization. Our observations indicate that the perceived difficulty of full-batch training is largely the result of its optimization properties and the disproportionate time and effort spent by the ML community tuning optimizers and hyperparameters for small-batch training.
-
 Robbing the Fed: Directly Obtaining Private Data in Federated Learning with Modified ModelsLiam Fowl , Jonas Geiping , Wojciech Czaja , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2022
Robbing the Fed: Directly Obtaining Private Data in Federated Learning with Modified ModelsLiam Fowl , Jonas Geiping , Wojciech Czaja , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2022Federated learning has quickly gained popularity with its promises of increased user privacy and efficiency. Previous works have shown that federated gradient updates contain information that can be used to approximately recover user data in some situations. These previous attacks on user privacy have been limited in scope and do not scale to gradient updates aggregated over even a handful of data points, leaving some to conclude that data privacy is still intact for realistic training regimes. In this work, we introduce a new threat model based on minimal but malicious modifications of the shared model architecture which enable the server to directly obtain a verbatim copy of user data from gradient updates without solving difficult inverse problems. Even user data aggregated over large batches – where previous methods fail to extract meaningful content – can be reconstructed by these minimally modified models.
-
 Fishing for User Data in Large-Batch Federated Learning via Gradient MagnificationYuxin Wen , Jonas Geiping , Liam Fowl , Micah Goldblum , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2022
Fishing for User Data in Large-Batch Federated Learning via Gradient MagnificationYuxin Wen , Jonas Geiping , Liam Fowl , Micah Goldblum , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2022Federated learning (FL) has rapidly risen in popularity due to its promise of privacy and efficiency. Previous works have exposed privacy vulnerabilities in the FL pipeline by recovering user data from gradient updates. However, existing attacks fail to address realistic settings because they either 1) require toy settings with very small batch sizes, or 2) require unrealistic and conspicuous architecture modifications. We introduce a new strategy that dramatically elevates existing attacks to operate on batches of arbitrarily large size, and without architectural modifications. Our model-agnostic strategy only requires modifications to the model parameters sent to the user, which is a realistic threat model in many scenarios. We demonstrate the strategy in challenging large-scale settings, obtaining high-fidelity data extraction in both cross-device and cross-silo federated learning.
-
 Plug-In Inversion: Model-Agnostic Inversion for Vision with Data AugmentationsAmin Ghiasi , Hamid Kazemi , Steven Reich , Chen Zhu , Micah Goldblum , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2022
Plug-In Inversion: Model-Agnostic Inversion for Vision with Data AugmentationsAmin Ghiasi , Hamid Kazemi , Steven Reich , Chen Zhu , Micah Goldblum , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2022Existing techniques for model inversion typically rely on hard-to-tune regularizers, such as total variation or feature regularization, which must be individually calibrated for each network in order to produce adequate images. In this work, we introduce Plug-In Inversion, which relies on a simple set of augmentations and does not require excessive hyper-parameter tuning. Under our proposed augmentation-based scheme, the same set of augmentation hyper-parameters can be used for inverting a wide range of image classification models, regardless of input dimensions or the architecture. We illustrate the practicality of our approach by inverting Vision Transformers (ViTs) and Multi-Layer Perceptrons (MLPs) trained on the ImageNet dataset, tasks which to the best of our knowledge have not been successfully accomplished by any previous works.
-
 Can You Learn the Same Model Twice? Investigating Reproducibility and Double Descent from the Decision Boundary PerspectiveGowthami Somepalli , Liam Fowl , Arpit Bansal , Ping Ye-Chiang , Yehuda Dar , Richard Baraniuk , Micah Goldblum , and Tom GoldsteinConference on Computer Vision and Pattern Recognition (CVPR), 2022
Can You Learn the Same Model Twice? Investigating Reproducibility and Double Descent from the Decision Boundary PerspectiveGowthami Somepalli , Liam Fowl , Arpit Bansal , Ping Ye-Chiang , Yehuda Dar , Richard Baraniuk , Micah Goldblum , and Tom GoldsteinConference on Computer Vision and Pattern Recognition (CVPR), 2022We discuss methods for visualizing neural network decision boundaries and decision regions. We use these visualizations to investigate issues related to reproducibility and generalization in neural network training. We observe that changes in model architecture (and its associate inductive bias) cause visible changes in decision boundaries, while multiple runs with the same architecture yield results with strong similarities, especially in the case of wide architectures. We also use decision boundary methods to visualize double descent phenomena. We see that decision boundary reproducibility depends strongly on model width. Near the threshold of interpolation, neural network decision boundaries become fragmented into many small decision regions, and these regions are non-reproducible. Meanwhile, very narrows and very wide networks have high levels of reproducibility in their decision boundaries with relatively few decision regions. We discuss how our observations relate to the theory of double descent phenomena in convex models.
-
 Autoregressive Perturbations for Data PoisoningPedro Sandoval-Segura , Vasu Singla , Jonas Geiping , Micah Goldblum , Tom Goldstein , and David W JacobsAdvances in Neural Information Processing Systems (NeurIPS), 2022
Autoregressive Perturbations for Data PoisoningPedro Sandoval-Segura , Vasu Singla , Jonas Geiping , Micah Goldblum , Tom Goldstein , and David W JacobsAdvances in Neural Information Processing Systems (NeurIPS), 2022The prevalence of data scraping from social media as a means to obtain datasets has led to growing concerns regarding unauthorized use of data. Data poisoning attacks have been proposed as a bulwark against scraping, as they make data "unlearnable" by adding small, imperceptible perturbations. Unfortunately, existing methods require knowledge of both the target architecture and the complete dataset so that a surrogate network can be trained, the parameters of which are used to generate the attack. In this work, we introduce autoregressive (AR) poisoning, a method that can generate poisoned data without access to the broader dataset. The proposed AR perturbations are generic, can be applied across different datasets, and can poison different architectures. Compared to existing unlearnable methods, our AR poisons are more resistant against common defenses such as adversarial training and strong data augmentations. Our analysis further provides insight into what makes an effective data poison.
-
 Pre-Train Your Loss: Easy Bayesian Transfer Learning with Informative PriorsRavid Shwartz-Ziv , Micah Goldblum , Hossein Souri , Sanyam Kapoor , Chen Zhu , Yann LeCun , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2022
Pre-Train Your Loss: Easy Bayesian Transfer Learning with Informative PriorsRavid Shwartz-Ziv , Micah Goldblum , Hossein Souri , Sanyam Kapoor , Chen Zhu , Yann LeCun , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2022Deep learning is increasingly moving towards a transfer learning paradigm whereby large foundation models are fine-tuned on downstream tasks, starting from an initialization learned on the source task. But an initialization contains relatively little information about the source task. Instead, we show that we can learn highly informative posteriors from the source task, through supervised or self-supervised approaches, which then serve as the basis for priors that modify the whole loss surface on the downstream task. This simple modular approach enables significant performance gains and more data-efficient learning on a variety of downstream classification and segmentation tasks, serving as a drop-in replacement for standard pre-training strategies. These highly informative priors also can be saved for future use, similar to pre-trained weights, and stand in contrast to the zero-mean isotropic uninformative priors that are typically used in Bayesian deep learning.
-
 End-to-end Algorithm Synthesis with Recurrent Networks: Logical Extrapolation Without OverthinkingArpit Bansal , Avi Schwarzschild , Eitan Borgnia , Zeyad Emam , Furong Huang , Micah Goldblum , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2022
End-to-end Algorithm Synthesis with Recurrent Networks: Logical Extrapolation Without OverthinkingArpit Bansal , Avi Schwarzschild , Eitan Borgnia , Zeyad Emam , Furong Huang , Micah Goldblum , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2022Machine learning systems perform well on pattern matching tasks, but their ability to perform algorithmic or logical reasoning is not well understood. One important reasoning capability is algorithmic extrapolation, in which models trained only on small/simple reasoning problems can synthesize complex strategies for large/complex problems at test time. Algorithmic extrapolation can be achieved through recurrent systems, which can be iterated many times to solve difficult reasoning problems. We observe that this approach fails to scale to highly complex problems because behavior degenerates when many iterations are applied – an issue we refer to as "overthinking." We propose a recall architecture that keeps an explicit copy of the problem instance in memory so that it cannot be forgotten. We also employ a progressive training routine that prevents the model from learning behaviors that are specific to iteration number and instead pushes it to learn behaviors that can be repeated indefinitely. These innovations prevent the overthinking problem, and enable recurrent systems to solve extremely hard extrapolation tasks.
-
 Sleeper agent: Scalable hidden trigger backdoors for neural networks trained from scratchHossein Souri , Micah Goldblum , Liam Fowl , Rama Chellappa , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2022
Sleeper agent: Scalable hidden trigger backdoors for neural networks trained from scratchHossein Souri , Micah Goldblum , Liam Fowl , Rama Chellappa , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2022As the curation of data for machine learning becomes increasingly automated, dataset tampering is a mounting threat. Backdoor attackers tamper with training data to embed a vulnerability in models that are trained on that data. This vulnerability is then activated at inference time by placing a "trigger" into the model’s input. Typical backdoor attacks insert the trigger directly into the training data, although the presence of such an attack may be visible upon inspection. In contrast, the Hidden Trigger Backdoor Attack achieves poisoning without placing a trigger into the training data at all. However, this hidden trigger attack is ineffective at poisoning neural networks trained from scratch. We develop a new hidden trigger attack, Sleeper Agent, which employs gradient matching, data selection, and target model re-training during the crafting process. Sleeper Agent is the first hidden trigger backdoor attack to be effective against neural networks trained from scratch. We demonstrate its effectiveness on ImageNet and in black-box settings.
-
 Where do Models go Wrong? Parameter-Space Saliency Maps for ExplainabilityRoman Levin , Manli Shu , Eitan Borgnia , Furong Huang , Micah Goldblum , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2022
Where do Models go Wrong? Parameter-Space Saliency Maps for ExplainabilityRoman Levin , Manli Shu , Eitan Borgnia , Furong Huang , Micah Goldblum , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2022Conventional saliency maps highlight input features to which neural network predictions are highly sensitive. We take a different approach to saliency, in which we identify and analyze the network parameters, rather than inputs, which are responsible for erroneous decisions. We find that samples which cause similar parameters to malfunction are semantically similar. We also show that pruning the most salient parameters for a wrongly classified sample often improves model behavior. Furthermore, fine-tuning a small number of the most salient parameters on a single sample results in error correction on other samples that are misclassified for similar reasons. Based on our parameter saliency method, we also introduce an input-space saliency technique that reveals how image features cause specific network components to malfunction. Further, we rigorously validate the meaningfulness of our saliency maps on both the dataset and case-study levels.
-
 Chroma-VAE: Mitigating Shortcut Learning with Generative ClassifiersWanqian Yang , Polina Kirichenko , Micah Goldblum , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2022
Chroma-VAE: Mitigating Shortcut Learning with Generative ClassifiersWanqian Yang , Polina Kirichenko , Micah Goldblum , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2022Deep neural networks are susceptible to shortcut learning, using simple features to achieve low training loss without discovering essential semantic structure. Contrary to prior belief, we show that generative models alone are not sufficient to prevent shortcut learning, despite an incentive to recover a more comprehensive representation of the data than discriminative approaches. However, we observe that shortcuts are preferentially encoded with minimal information, a fact that generative models can exploit to mitigate shortcut learning. In particular, we propose Chroma-VAE, a two-pronged approach where a VAE classifier is initially trained to isolate the shortcut in a small latent subspace, allowing a secondary classifier to be trained on the complementary, shortcut-free latent subspace. In addition to demonstrating the efficacy of Chroma-VAE on benchmark and real-world shortcut learning tasks, our work highlights the potential for manipulating the latent space of generative classifiers to isolate or interpret specific correlations.
-
 PAC-Bayes Compression Bounds So Tight That They Can Explain GeneralizationSanae Lotfi , Marc Anton Finzi , Sanyam Kapoor , Andres Potapczynski , Micah Goldblum , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2022
PAC-Bayes Compression Bounds So Tight That They Can Explain GeneralizationSanae Lotfi , Marc Anton Finzi , Sanyam Kapoor , Andres Potapczynski , Micah Goldblum , and Andrew Gordon WilsonAdvances in Neural Information Processing Systems (NeurIPS), 2022While there has been progress in developing non-vacuous generalization bounds for deep neural networks, these bounds tend to be uninformative about why deep learning works. In this paper, we develop a compression approach based on quantizing neural network parameters in a linear subspace, profoundly improving on previous results to provide state-of-the-art generalization bounds on a variety of tasks, including transfer learning. We use these tight bounds to better understand the role of model size, equivariance, and the implicit biases of optimization, for generalization in deep learning. Notably, we find large models can be compressed to a much greater extent than previously known, encapsulating Occam’s razor.
















2021
-
 Can You Learn an Algorithm? Generalizing from Easy to Hard Problems with Recurrent NetworksAvi Schwarzschild , Eitan Borgnia , Arjun Gupta , Furong Huang , Uzi Vishkin , Micah Goldblum , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2021
Can You Learn an Algorithm? Generalizing from Easy to Hard Problems with Recurrent NetworksAvi Schwarzschild , Eitan Borgnia , Arjun Gupta , Furong Huang , Uzi Vishkin , Micah Goldblum , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2021Deep neural networks are powerful machines for visual pattern recognition, but reasoning tasks that are easy for humans may still be difficult for neural models. Humans possess the ability to extrapolate reasoning strategies learned on simple problems to solve harder examples, often by thinking for longer. For example, a person who has learned to solve small mazes can easily extend the very same search techniques to solve much larger mazes by spending more time. In computers, this behavior is often achieved through the use of algorithms, which scale to arbitrarily hard problem instances at the cost of more computation. In contrast, the sequential computing budget of feed-forward neural networks is limited by their depth, and networks trained on simple problems have no way of extending their reasoning to accommodate harder problems. In this work, we show that recurrent networks trained to solve simple problems with few recurrent steps can indeed solve much more complex problems simply by performing additional recurrences during inference. We demonstrate this algorithmic behavior of recurrent networks on prefix sum computation, mazes, and chess. In all three domains, networks trained on simple problem instances are able to extend their reasoning abilities at test time simply by "thinking for longer."
-
 Prepare for the Worst: Generalizing across Domain Shifts with Adversarial Batch NormalizationManli Shu , Zuxuan Wu , Micah Goldblum , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2021
Prepare for the Worst: Generalizing across Domain Shifts with Adversarial Batch NormalizationManli Shu , Zuxuan Wu , Micah Goldblum , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2021Adversarial training is the industry standard for producing models that are robust to small adversarial perturbations. However, machine learning practitioners need models that are robust to domain shifts that occur naturally, such as changes in the style or illumination of input images. Such changes in input distribution have been effectively modeled as shifts in the mean and variance of deep image features. We adapt adversarial training by adversarially perturbing these feature statistics, rather than image pixels, to produce models that are robust to domain shift. We also visualize images from adversarially crafted distributions. Our method, Adversarial Batch Normalization (AdvBN), significantly improves the performance of ResNet-50 on ImageNet-C (+8.1%), Stylized-ImageNet (+6.7%), and ImageNet-Instagram (+3.9%) over standard training practices. In addition, we demonstrate that AdvBN can also improve generalization on semantic segmentation.
-
 Adversarial Examples Make Strong PoisonsLiam Fowl , Micah Goldblum , Ping-yeh Chiang , Jonas Geiping , Wojtek Czaja , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2021
Adversarial Examples Make Strong PoisonsLiam Fowl , Micah Goldblum , Ping-yeh Chiang , Jonas Geiping , Wojtek Czaja , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2021The adversarial machine learning literature is largely partitioned into evasion attacks on testing data and poisoning attacks on training data. In this work, we show that adversarial examples, originally intended for attacking pre-trained models, are even more effective for data poisoning than recent methods designed specifically for poisoning. Our findings indicate that adversarial examples, when assigned the original label of their natural base image, cannot be used to train a classifier for natural images. Furthermore, when adversarial examples are assigned their adversarial class label, they are useful for training. This suggests that adversarial examples contain useful semantic content, just with the “wrong” labels (according to a network, but not a human). Our method, adversarial poisoning, is substantially more effective than existing poisoning methods for secure dataset release, and we release a poisoned version of ImageNet, ImageNet-P, to encourage research into the strength of this form of data obfuscation.
-
 Data Augmentation for Meta-LearningRenkun Ni , Micah Goldblum , Amr Sharaf , Kezhi Kong , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2021
Data Augmentation for Meta-LearningRenkun Ni , Micah Goldblum , Amr Sharaf , Kezhi Kong , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2021Conventional image classifiers are trained by randomly sampling mini-batches of images. To achieve state-of-the-art performance, practitioners use sophisticated data augmentation schemes to expand the amount of training data available for sampling. In contrast, meta-learning algorithms sample support data, query data, and tasks on each training step. In this complex sampling scenario, data augmentation can be used not only to expand the number of images available per class, but also to generate entirely new classes/tasks. We systematically dissect the meta-learning pipeline and investigate the distinct ways in which data augmentation can be integrated at both the image and class levels. Our proposed meta-specific data augmentation significantly improves the performance of meta-learners on few-shot classification benchmarks.
-
 Just How Toxic is Data Poisoning? A Unified Benchmark for Backdoor and Data Poisoning AttacksAvi Schwarzschild , Micah Goldblum , Arjun Gupta , John P Dickerson , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2021
Just How Toxic is Data Poisoning? A Unified Benchmark for Backdoor and Data Poisoning AttacksAvi Schwarzschild , Micah Goldblum , Arjun Gupta , John P Dickerson , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2021Data poisoning and backdoor attacks manipulate training data in order to cause models to fail during inference. A recent survey of industry practitioners found that data poisoning is the number one concern among threats ranging from model stealing to adversarial attacks. However, it remains unclear exactly how dangerous poisoning methods are and which ones are more effective considering that these methods, even ones with identical objectives, have not been tested in consistent or realistic settings. We observe that data poisoning and backdoor attacks are highly sensitive to variations in the testing setup. Moreover, we find that existing methods may not generalize to realistic settings. While these existing works serve as valuable prototypes for data poisoning, we apply rigorous tests to determine the extent to which we should fear them. In order to promote fair comparison in future work, we develop standardized benchmarks for data poisoning and backdoor attacks.
-
 LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial RecognitionValeriia Cherepanova , Micah Goldblum , Harrison Foley , Shiyuan Duan , John P Dickerson , Gavin Taylor , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2021
LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial RecognitionValeriia Cherepanova , Micah Goldblum , Harrison Foley , Shiyuan Duan , John P Dickerson , Gavin Taylor , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2021Facial recognition systems are increasingly deployed by private corporations, government agencies, and contractors for consumer services and mass surveillance programs alike. These systems are typically built by scraping social media profiles for user images. Adversarial perturbations have been proposed for bypassing facial recognition systems. However, existing methods fail on full-scale systems and commercial APIs. We develop our own adversarial filter that accounts for the entire image processing pipeline and is demonstrably effective against industrial-grade pipelines that include face detection and large scale databases. Additionally, we release an easy-to-use webtool that significantly degrades the accuracy of Amazon Rekognition and the Microsoft Azure Face Recognition API, reducing the accuracy of each to below 1%.
-
 The Intrinsic Dimension of Images and Its Impact on LearningPhillip Pope , Chen Zhu , Ahmed Abdelkader , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2021
The Intrinsic Dimension of Images and Its Impact on LearningPhillip Pope , Chen Zhu , Ahmed Abdelkader , Micah Goldblum , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2021It is widely believed that natural image data exhibits low-dimensional structure despite the high dimensionality of conventional pixel representations. This idea underlies a common intuition for the remarkable success of deep learning in computer vision. In this work, we apply dimension estimation tools to popular datasets and investigate the role of low-dimensional structure in deep learning. We find that common natural image datasets indeed have very low intrinsic dimension relative to the high number of pixels in the images. Additionally, we find that low dimensional datasets are easier for neural networks to learn, and models solving these tasks generalize better from training to test data. Along the way, we develop a technique for validating our dimension estimation tools on synthetic data generated by GANs allowing us to actively manipulate the intrinsic dimension by controlling the image generation process.
-
 Strong Data Augmentation Sanitizes Poisoning and Backdoor Attacks Without an Accuracy TradeoffEitan Borgnia , Valeriia Cherepanova , Liam Fowl , Amin Ghiasi , Jonas Geiping , Micah Goldblum , Tom Goldstein , and Arjun GuptaIn ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2021
Strong Data Augmentation Sanitizes Poisoning and Backdoor Attacks Without an Accuracy TradeoffEitan Borgnia , Valeriia Cherepanova , Liam Fowl , Amin Ghiasi , Jonas Geiping , Micah Goldblum , Tom Goldstein , and Arjun GuptaIn ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2021Data poisoning and backdoor attacks manipulate victim models by maliciously modifying training data. In light of this growing threat, a recent survey of industry professionals revealed heightened fear in the private sector regarding data poisoning. Many previous defenses against poisoning either fail in the face of increasingly strong attacks, or they significantly degrade performance. However, we find that strong data augmentations, such as mixup and CutMix, can significantly diminish the threat of poisoning and backdoor attacks without trading off performance. We further verify the effectiveness of this simple defense against adaptive poisoning methods, and we compare to baselines including the popular differentially private SGD (DP-SGD) defense. In the context of backdoors, CutMix greatly mitigates the attack while simultaneously increasing validation accuracy by 9%.
-
 Adversarial Attacks on Machine Learning Systems for High-Frequency TradingMicah Goldblum , Avi Schwarzschild , Ankit B Patel , and Tom GoldsteinACM International Conference on AI in Finance (ICAIF), 2021
Adversarial Attacks on Machine Learning Systems for High-Frequency TradingMicah Goldblum , Avi Schwarzschild , Ankit B Patel , and Tom GoldsteinACM International Conference on AI in Finance (ICAIF), 2021Algorithmic trading systems are often completely automated, and deep learning is increasingly receiving attention in this domain. Nonetheless, little is known about the robustness properties of these models. We study valuation models for algorithmic trading from the perspective of adversarial machine learning. We introduce new attacks specific to this domain with size constraints that minimize attack costs. We further discuss how these attacks can be used as an analysis tool to study and evaluate the robustness properties of financial models. Finally, we investigate the feasibility of realistic adversarial attacks in which an adversarial trader fools automated trading systems into making inaccurate predictions.









2020
-
 Adversarially Robust Few-Shot Learning: A Meta-Learning ApproachMicah Goldblum , Liam Fowl , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2020
Adversarially Robust Few-Shot Learning: A Meta-Learning ApproachMicah Goldblum , Liam Fowl , and Tom GoldsteinAdvances in Neural Information Processing Systems (NeurIPS), 2020Previous work on adversarially robust neural networks for image classification requires large training sets and computationally expensive training procedures. On the other hand, few-shot learning methods are highly vulnerable to adversarial examples. The goal of our work is to produce networks which both perform well at few-shot classification tasks and are simultaneously robust to adversarial examples. We develop an algorithm, called Adversarial Querying (AQ), for producing adversarially robust meta-learners, and we thoroughly investigate the causes for adversarial vulnerability. Moreover, our method achieves far superior robust performance on few-shot image classification tasks, such as Mini-ImageNet and CIFAR-FS, than robust transfer learning.
-
 Unraveling Meta-Learning: Understanding Feature Representations for Few-Shot TasksMicah Goldblum , Steven Reich , Liam Fowl , Renkun Ni , Valeriia Cherepanova , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2020
Unraveling Meta-Learning: Understanding Feature Representations for Few-Shot TasksMicah Goldblum , Steven Reich , Liam Fowl , Renkun Ni , Valeriia Cherepanova , and Tom GoldsteinInternational Conference on Machine Learning (ICML), 2020Meta-learning algorithms produce feature extractors which achieve state-of-the-art performance on few-shot classification. While the literature is rich with meta-learning methods, little is known about why the resulting feature extractors perform so well. We develop a better understanding of the underlying mechanics of meta-learning and the difference between models trained using meta-learning and models which are trained classically. In doing so, we introduce and verify several hypotheses for why meta-learned models perform better. Furthermore, we develop a regularizer which boosts the performance of standard training routines for few-shot classification. In many cases, our routine outperforms meta-learning while simultaneously running an order of magnitude faster.
-
 Truth or Backpropaganda? An Empirical Investigation of Deep Learning TheoryMicah Goldblum , Jonas Geiping , Avi Schwarzschild , Michael Moeller , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2020
Truth or Backpropaganda? An Empirical Investigation of Deep Learning TheoryMicah Goldblum , Jonas Geiping , Avi Schwarzschild , Michael Moeller , and Tom GoldsteinInternational Conference on Learning Representations (ICLR), 2020We empirically evaluate common assumptions about neural networks that are widely held by practitioners and theorists alike. In this work, we: (1) prove the widespread existence of suboptimal local minima in the loss landscape of neural networks, and we use our theory to find examples; (2) show that small-norm parameters are not optimal for generalization; (3) demonstrate that ResNets do not conform to wide-network theories, such as the neural tangent kernel, and that the interaction between skip connections and batch normalization plays a role; (4) find that rank does not correlate with generalization or robustness in a practical setting.
-
 Adversarially Robust DistillationMicah Goldblum , Liam Fowl , Soheil Feizi , and Tom GoldsteinProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020
Adversarially Robust DistillationMicah Goldblum , Liam Fowl , Soheil Feizi , and Tom GoldsteinProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020Knowledge distillation is effective for producing small, high-performance neural networks for classification, but these small networks are vulnerable to adversarial attacks. This paper studies how adversarial robustness transfers from teacher to student during knowledge distillation. We find that a large amount of robustness may be inherited by the student even when distilled on only clean images. Second, we introduce Adversarially Robust Distillation (ARD) for distilling robustness onto student networks. In addition to producing small models with high test accuracy like conventional distillation, ARD also passes the superior robustness of large networks onto the student. In our experiments, we find that ARD student models decisively outperform adversarially trained networks of identical architecture in terms of robust accuracy, surpassing state-of-the-art methods on standard robustness benchmarks. Finally, we adapt recent fast adversarial training methods to ARD for accelerated robust distillation.
-
 Witchcraft: Efficient PGD Attacks with Random Step SizePing-Yeh Chiang , Jonas Geiping , Micah Goldblum , Tom Goldstein , Renkun Ni , Steven Reich , and Ali ShafahiIn ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2020
Witchcraft: Efficient PGD Attacks with Random Step SizePing-Yeh Chiang , Jonas Geiping , Micah Goldblum , Tom Goldstein , Renkun Ni , Steven Reich , and Ali ShafahiIn ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2020State-of-the-art adversarial attacks on neural networks use expensive iterative methods and numerous random restarts from different initial points. Iterative FGSM-based methods without restarts trade off performance for computational efficiency because they do not adequately explore the image space and are highly sensitive to the choice of step size. We propose a variant of Projected Gradient Descent (PGD) that uses a random step size to improve performance without resorting to expensive random restarts. Our method, Wide Iterative Stochastic crafting (WITCHcraft), achieves results superior to the classical PGD attack on the CIFAR-10 and MNIST data sets but without additional computational cost. This simple modification of PGD makes crafting attacks more economical, which is important in situations like adversarial training where attacks need to be crafted in real time.





2019
-
 Sheared Multi-Scale Weight Sharing for Multi-Spectral SuperresolutionMicah Goldblum , Liam Fowl , and Wojciech CzajaIn Algorithms, Technologies, and Applications for Multispectral and Hyperspectral Imagery XXV , 2019
Sheared Multi-Scale Weight Sharing for Multi-Spectral SuperresolutionMicah Goldblum , Liam Fowl , and Wojciech CzajaIn Algorithms, Technologies, and Applications for Multispectral and Hyperspectral Imagery XXV , 2019Deep learning approaches to single-image superresolution typically use convolutional neural networks. Convolutional layers introduce translation invariance to neural networks. However, other spatial invariants appear in imaging data. Two such invariances are scale invariance, similar features at multiple spacial scales, and shearing invariance. We investigate these invariances by using weight sharing between dilated and sheared convolutional kernels in the context of multi-spectral imaging data. Traditional pooling methods can extract features at coarse spacial levels. Our approach explores a finer range of scales. Additionally, our approach offers improved storage efficiency because dilated and sheared convolutions allows single trainable kernels to extract information at multiple spacial scales and shears without the costs of training and storing many filters, especially in multi-spectral imaging where data representations are complex.
